瑞莎智核 DX-M1/DX-M1M
产品概述
- DX-M1
- DX-M1M
瑞莎智核 DX-M1 是一款基于 DEEPX 公司 DX-M1 模组的高性能边缘 AI 加速算力模组,具有高能效、高精度计算和易用性等特性,专为边缘计算场景和机器视觉优化设计。
瑞莎智核 DX-M1 模组目前兼容多款单板计算机(SBC)。
- 高能效设计
采用高能效设计,具有出色的推理性能和低功耗,实现 25 TOPS 算力仅需 3-5W 功耗;
- 高精度计算
使用 IQ8™(智能量化8位整型)技术,精度与 GPU 的 FP32 保持相同的精度水平。
- 易用性
- AI 框架:支持 ONNX、PyTorch、TensorFlow。
- 系统支持:支持 Ubuntu、Debian 等主流操作系统。
- 标准化接口:采用标准 M.2 2280 M Key 尺寸,兼容主流工业及嵌入式设备。
瑞莎智核 DX-M1M 是一款紧凑型边缘 AI 加速模组,基于 DEEPX DX-M1M,面向嵌入式与工业系统的端侧推理场景,支持快速集成与部署。
该 AI 处理器可提供最高 25 TOPS(INT8)算力,典型功耗为 3W,适用于对功耗预算敏感的边缘应用。模组采用标准 M.2 M + B Key(PCIe Gen3 ×2)外形与接口形态,集成板载内存与 QSPI Flash,并兼容 x86 / ARM 主机平台及多种操作系统,可为从概念验证到量产部署的端侧 AI 负载提供可扩展的加速方案。
- 高能效设计
在典型功耗 3W 下实现最高 25 TOPS 推理性能,为边缘与嵌入式部署提供优异的每瓦性能。
- 易用性
基于标准 PCIe 模组接口形态,并提供广泛的操作系统与框架支持,便于快速集成并缩短部署周期。
- 标准接口:M.2 M + B Key(PCIe Gen3 ×2)
- 主机平台:x86 / ARM
- 系统支持:Windows 10 / 11,Ubuntu 24.04 / 22.04 / 20.04 LTS,Docker
- AI 框架:通过 DX-COM 编译器转换,兼容 TensorFlow、ONNX、Keras、PyTorch 等框架
产品外观
- DX-M1
- DX-M1M
智核 DX-M1 模块正面

智核 DX-M1 模块背面
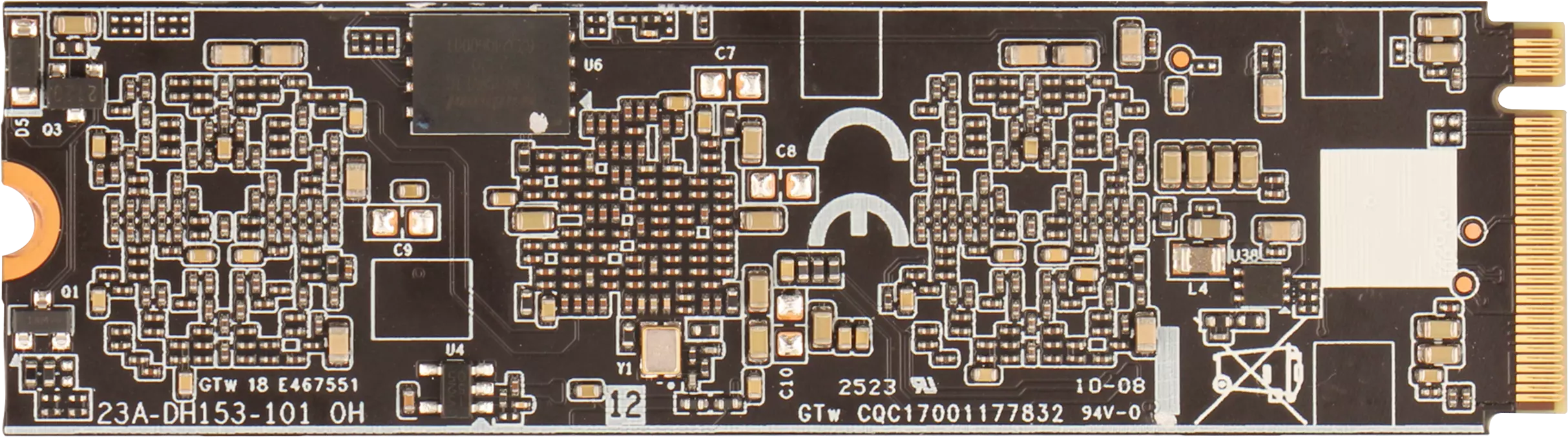
智核 DX-M1M 模块正面

智核 DX-M1M 模块背面

产品规格
- DX-M1
- DX-M1M
| 产品 | 智核 DX-M1M |
|---|---|
| 类型 | AI 算力模组 |
| AI 性能 | 25 TOPS |
| 外形规格 | M.2 M key |
| 尺寸 | 22 × 80 mm |
| 接口 | PCIe Gen 3 ×4 |
| 内存配置 | 4GB LPDDR5 + 1Gbit QSPI NAND Flash |
| 调试接口 | UART0, JTAG1 |
| 支持 AI 框架 | PyTorch, ONNX, TensorFlow |
| 支持操作系统 | Linux (Ubuntu, Debian) |
| 支持硬件架构 | ARM |
| 产品 | 智核 DX-M1M |
|---|---|
| 类型 | AI 加速模组 |
| AI 性能 | 25 TOPS |
| 内存 | 1GB LPDDR4X@4266 MT/s |
| 存储 | QSPI 1Gbit NAND / NOR Flash |
| 模块接口 | PCIe Gen3 x2 |
| 主机接口 | PCIe Gen3 x4(支持 Gen 1 / 2 / 3 与 x1 / x2) |
| 软件 | 支持 Windows 10 / 11,Ubuntu 24.04 / 22.04 / 20.04 LTS,Docker |
| AI 框架 | 通过 DX-COM 编译器转换支持 TensorFlow、ONNX、Keras、PyTorch |
| 工作温度 | -25°C ~ 65°C(非限频) / -25°C ~ 85°C(限频) |
| 主机平台 | x86 / ARM |
| 功耗 | 3W(典型值) |
| 外形尺寸 | M.2 M + B Key,22mm × 42mm |
应用场景
- 智能摄像
- 自动驾驶
- 消费电子
- 安防监控
- 边缘计算
- 智慧出行