QAIRT 模型移植
QAIRT 为开发者提供了在 Qualcomm® 硬件加速器上移植和部署 AI 模型所需的所有工具。 本文档将详细通过使用 QAIRT 对 resnet50 目标识别模型进行移植, 并在板端 Ubuntu 系统上使用 NPU 推理模型为示例,完整讲述使用 QAIRT SDK 将模型移植到 NPU 硬件的方法。
模型移植流程
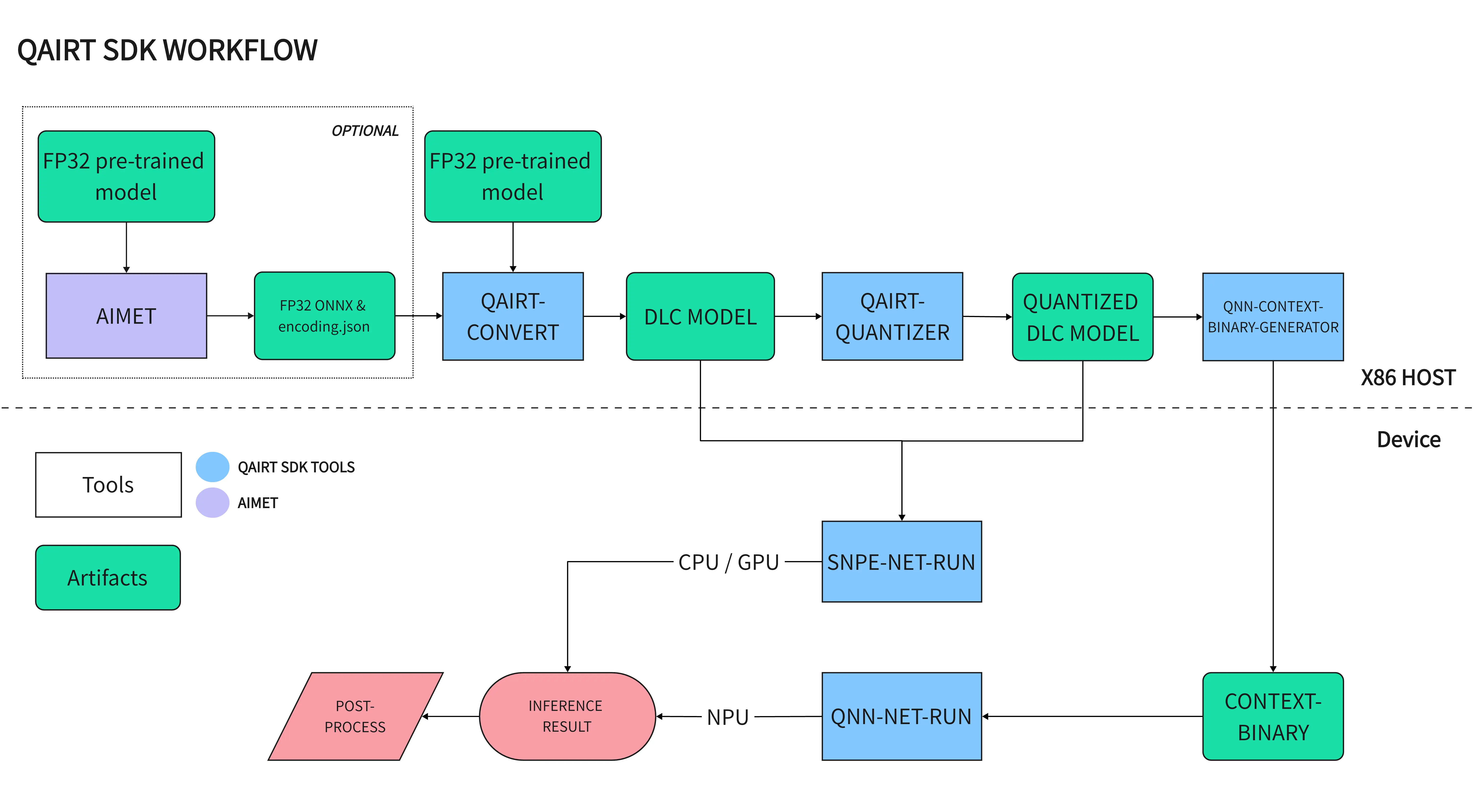
QAIRT WORKFLOW
要将主流 AI 模型框架格式模型 (Pytorch, Tensorflow, TFLite, ONNX) 移植到 Qualcomm NPU 进行硬件加速推理需要将模型转换成
Qualcomm NPU 专用的 Context-Binary 格式模型。要转换成 Context-Binary 格式模型需要进行以下步骤:
- 准备预训练好的浮点模型
- 使用 AIMET 对预训练模型进行高效模型优化与量化 (可选)
- 使用 QAIRT 工具将模型转换成浮点 DLC 格式
- 使用 QAIRT 工具将浮点 DLC 模型进行量化
- 使用 QAIRT 工具将 DLC 模型转换成 Context-Binary 格式模型
- 使用 QAIRT 工具使用 NPU 推理 Context-Binary 模型
以下以 resnet50 为例,完整演示上述流程。
第一部分:主机端模型转换
步骤 1:准备 QAIRT 开发环境
请参考 QAIRT SDK 安装 配置好 QAIRT 工作环境
步骤 2:准备预训练模型
请在 QAIRT SDK 中克隆 resnet50 例子仓库
cd qairt/2.42.0.251225/examples/Models/
git clone https://github.com/ZIFENG278/resnet50_qairt_example.git && cd resnet50_qairt_example
这里以 pytorch resnet50 为例子, 导出输入行状为 (batch_size,3,224,224) 的 ONNX 模型。请使用以下脚本导出模型:
python3 export_onnx.py
导出的 onnx 模型保存在 resnet50.onnx
步骤 3:使用 AIMET 量化(可选)
AIMET 是独立的开源模型量化库,不包含在 QAIRT SDK 中,在对模型进行移植前, 推荐使用 AIMET 对预训练模型进行模型优化与量化,这会最大程度提升模型在推理时的性能和保持模型原有精度。
使用 AIMET 量化与 QAIRT 里的量化并不冲突,AIMET 属于高级量化,QAIRT 量化是普通线型量化。
- AIMET 安装请参考 AIMET 量化工具
- AIMET 使用请参考 AIMET 使用例子
步骤 4:DLC 模型转换
使用 QAIRT SDK 中的 qairt-converter 可以将 Onnx/TensorFlow/TFLite/PyTorch 框架模型和 AIMET 的输出文件转换成 DLC (Deep Learning Container) 模型文件。
qairt-converter 会通过模型文件的后缀名自动识别模型框架。
此文档后续部分分为使用经过 AIMET 优化与量化的模型文件和原始 ONNX 模型文件的移植步骤,请注意区分。
- AIMET
- Pretrained ONNX
qairt-converter --input_network ./aimet_quant/resnet50.onnx --quantization_overrides ./aimet_quant/resnet50.encodings --output_path resnet50.dlc -d 'input' 1,3,224,224
qairt-converter 会生成一个量化 DLC 格式的模型文件,保存为 resnet50_aimet.dlc
qairt-converter --input_network ./resnet50.onnx -d 'input' 1,3,224,224
qairt-converter 会生成一个浮点 DLC 格式的模型文件,保存为 resnet50.dlc
此 DLC 文件可以使用 Qualcomm® Neural Processing SDK API 使用 CPU / GPU 推理,详细请参考 SNPE 文档
关于更多 qairt-converter 使用方法请参考 qairt-converter。
步骤 5:量化 DLC 模型
AIMET 模型经过 qairt-converter 得到的 DLC 模型已经是量化模型,使用 AIMET 模型可以跳过此量化步骤。
NPU 仅支持经过量化后的模型,在转换成 Context-Binary 格式模型前,需要将浮点 DLC 模型进行量化,
QAIRT 提供了一个量化工具 qairt-quantizer,可使用量化算法将 DLC 模型量化为 INT8/INT16 类型。
准备校准集合
scripts 里的 create_resnet50_raws.py 脚本可以制作 resnet50 模型输入的 raw 格式文件作为量化输入
cd scripts
python3 create_resnet50_raws.py --dest ../data/calibration/crop --img_folder ../data/calibration/ --size 224
准备校准集合文件列表
scripts 里的 create_file_list.py 脚本可以制作模型量化校准文件列表
cd scripts
python3 create_file_list.py --input_dir ../data/calibration/crop/ --output_filename ../model/calib_list.txt -e *.raw
生成的 calib_list.txt 里是校准 raw 文件的绝对路经
进行 DLC 模型量化
cd model
qairt-quantizer --input_dlc ./resnet50.dlc --input_list ./calib_list.txt --output_dlc resnet50_quantized.dlc
生成目标量化模型保存在 resnet50_quantized.dlc。关于更多 qairt-quantizer 使用方法请参考 qairt-quantizer。
步骤 6:生成 Context-Binary 模型
量化后的 DLC 模型在使用 NPU 进行推理前,需要将 DLC 模型转换成 Context-Binary 格式模型,转换的目的是将 DLC 模型图在目标硬件上运行的指令提前在 host 上准备好, 以便可以在 NPU 上进行推理,这样可以减少模型在板端的初始化时间和内存的消耗。
使用 QAIRT SDK 中的 qnn-context-binary-generator 可以将量化后的 DLC 格式模型转化成 Context-Binary 格式模型。
制作模型转换 config 文件
因为在 x86 host 进行特定硬件优化,这里需要制作两个 config 文件
SoC 架构对照表
| SoC | dsp_arch | soc_id |
|---|---|---|
| QCS6490 | v68 | 35 |
| SC8280XP | v68 | 37 |
| QCS9075 | v73 | 77 |
-
config_backend.json
- QCS6490
- SC8280XP
- QCS9075
请根据 SoC NPU 架构选择相应的 dsp_arch 和 soc_id, 这里以 QCS6490 SoC 为例子
X86 Linux PCvim config_backend.json{
"graphs": [
{
"graph_names": [
"resnet50"
],
"vtcm_mb": 0
}
],
"devices": [
{
"dsp_arch": "v68",
"soc_id": 35
}
]
}请根据 SoC NPU 架构选择相应的 dsp_arch 和 soc_id, 这里以 SC8280XP SoC 为例子
X86 Linux PCvim config_backend.json{
"graphs": [
{
"graph_names": [
"resnet50"
],
"vtcm_mb": 0
}
],
"devices": [
{
"dsp_arch": "v68",
"soc_id": 37
}
]
}请根据 SoC NPU 架构选择相应的 dsp_arch 和 soc_id, 这里以 QCS9075 SoC 为例子
X86 Linux PCvim config_backend.json{
"graphs": [
{
"graph_names": [
"resnet50"
],
"vtcm_mb": 0
}
],
"devices": [
{
"dsp_arch": "v73",
"soc_id": 77
}
]
}这里指定 4 个参数
graph_names: 模型的图名称列表,与未量化的 DCL 模型文件名同名 (不带后缀)vtcm_mb: 特定内存选项, 要使用设备的最大 VTCM 数量,请将值设置为 0dsp_arc: NPU 架构soc_id: SoC 的 id -
config_file.json
X86 Linux PCvim config_file.json{
"backend_extensions": {
"shared_library_path": "libQnnHtpNetRunExtensions.so",
"config_file_path": "config_backend.json"
}
}
关于详细构造 backend_extensions json 文件,请参考 qnn-htp-backend-extensions。
生成 Context-Binary
- AIMET
- Pretrained ONNX
qnn-context-binary-generator --model libQnnModelDlc.so --backend libQnnHtp.so --dlc_path resnet50.dlc --output_dir output --binary_file resnet50_quantized --config_file config_file.json
qnn-context-binary-generator --model libQnnModelDlc.so --backend libQnnHtp.so --dlc_path resnet50_quantized.dlc --output_dir output --binary_file resnet50_quantized --config_file config_file.json
生成 Context-Binary 保存在 output/resnet50_quantized.bin。关于更多 qnn-context-binary-generator 使用方法请参考 qnn-context-binary-generator。
第二部分:设备端 NPU 推理
模型转换完成后,以下步骤在目标设备上执行。使用 QAIRT SDK 中的 qnn-net-run 可以在板端使用 NPU 推理 Context-Binary 模型,此工具可以作为模型推理的测试工具。
板端克隆例子仓库
cd ~/
git clone https://github.com/ZIFENG278/resnet50_qairt_example.git
拷贝所需文件到板端
- QCS6490
- SC8280XP
- QCS9075
export PRODUCT_SOC=6490 DSP_ARCH=68
export PRODUCT_SOC=8280 DSP_ARCH=68
export PRODUCT_SOC=9075 DSP_ARCH=73
-
拷贝 Context-Binary 模型到板端
X86 Linux PCscp resnet50_quantized.bin <user>@<ip address>:/home/<user>/resnet50_qairt_example/model -
拷贝 qnn-net-run 可执行文件到板端
X86 Linux PCcd qairt/2.42.0.251225/bin/aarch64-oe-linux-gcc11.2
scp qnn-net-run <user>@<ip address>:/home/<user>/resnet50_qairt_example/model -
拷贝 qnn-net-run 所需动态库到板端
X86 Linux PCcd qairt/2.42.0.251225/lib/aarch64-oe-linux-gcc11.2
scp libQnnHtp.so libQnnHtpV${DSP_ARCH}Stub.so <user>@<ip address>:/home/<user>/resnet50_qairt_example/model -
拷贝 NPU 架构专用动态库文件到板端
请根据 SoC NPU 架构选择相应的 hexagon 文件夹, 这里以 QCS6490 为例子
X86 Linux PCcd qairt/2.42.0.251225/lib/hexagon-v${DSP_ARCH}/unsigned
scp ./libQnnHtpV${DSP_ARCH}Skel.so <user>@<ip address>:/home/<user>/resnet50_qairt_example/model
板端推理
qnn-net-run 推理
-
准备测试输入数据
Context-Binary 模型输入为 raw 数据, 需要先准备模型输入的测试 raw 数据, 与输入数据的列表
Devicecd scripts
python3 create_resnet50_raws.py --dest ../data/test/crop --img_folder ../data/test/ --size 224
python3 create_file_list.py --input_dir ../data/test/crop/ --output_filename ../model/test_list.txt -e *.raw -r -
执行模型推理
Devicecd model
./qnn-net-run --backend ./libQnnHtp.so --retrieve_context ./resnet50_quantized.bin --input_list ./test_list.txt --output_dir output_bin结果保存在
output_bin中。关于更多qnn-net-run使用方法请参考 qnn-net-run。
结果验证
可以使用 python 脚本进行结果验证
cd scripts
python3 show_resnet50_classifications.py --input_list ../model/test_list.txt -o ../model/output_bin/ --labels_file ../data/imagenet_classes.txt
$ python3 show_resnet50_classifications.py --input_list ../model/test_list.txt -o ../model/output_bin/ --labels_file ../data/imagenet_classes.txt
Classification results
../data/test/crop/ILSVRC2012_val_00003441.raw 21.740574 402 acoustic guitar
../data/test/crop/ILSVRC2012_val_00008465.raw 23.423716 927 trifle
../data/test/crop/ILSVRC2012_val_00010218.raw 12.623559 281 tabby
../data/test/crop/ILSVRC2012_val_00044076.raw 18.093769 376 proboscis monkey
通过结果打印与测试图片内容对比,可以确认 resnet50 模型移植到 Qualcomm® NPU 上输出的结果正确。

resnet50 input images