RKLLM Qwen2-VL
Qwen2-VL 是由阿里巴巴开发的一款多模态视觉语言模型(VLM)。 该模型具备卓越的视觉感知能力,能够自适应处理各种分辨率与比例的图像,并支持对 20 分钟以上长视频的深度理解。 此外,Qwen2-VL 拥有强大的多语言支持,并能作为智能体(Agent)胜任手机操控与机器人指令下达等复杂任务。 本文档将介绍如何使用 RKLLM 工具链,将 Qwen2-VL-2B-Instruct 视觉多模态模型部署到 RK3588 平台,并利用其内置 NPU 实现高效的硬件加速推理。
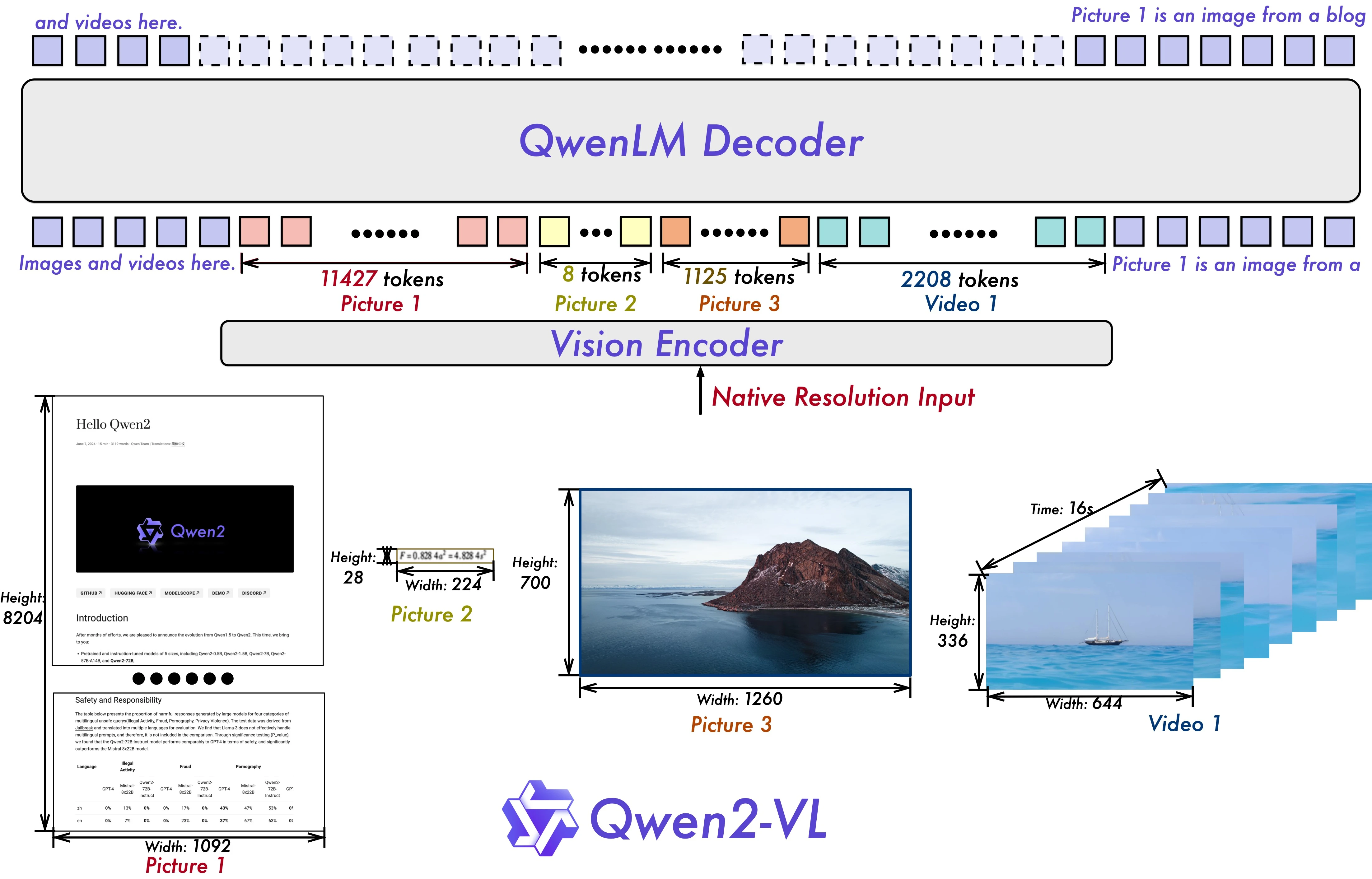
快速开始
下载示例
从 ModelScope 下载完整示例。
参考虚拟环境使用创建虚拟环境。
Device
python3 -m venv .venv && source .venv/bin/activate
pip install -U modelscope
modelscope download --model radxa/Qwen2-VL-2B-RKLLM --local_dir ./Qwen2-VL-2B-RKLLM
运行示例
Device
cd Qwen2-VL-2B-RKLLM/demo_Linux_aarch64/
export LD_LIBRARY_PATH=./lib
chmod +x ./demo
./demo demo.jpg ../qwen2_vl_2b_vision_rk3588.rknn ../qwen2-vl-2b-instruct_W8A8_rk3588.rkllm 2048 4096 3 "<|vision_start|>" "<|vision_end|>" "<|image_pad|>"
完整转换流程
激活虚拟环境
虚拟环境配置参考创建虚拟环境。
X64 Linux PC
conda activate rkllm
pip install -U huggingface_hub
下载模型
X64 Linux PC
cd RK-SDK/rknn-llm/examples/multimodal_model_demo/
hf download Qwen/Qwen2-VL-2B-Instruct --local-dir ./Qwen2-VL-2B-Instruct
模型转换
生成静态位置编码。
X64 Linux PC
python export/export_vision_qwen2.py --step 1 --path ./Qwen2-VL-2B-Instruct
| 参数名称 | 必要性 | 描述 | 选项 |
|---|---|---|---|
step | 必要 | 导出步骤 | 1/2,当 step==1 时仅生成 cu_seqlens 和 rotary_pos_emb,当 step==2 时导出 ONNX,需要先执行 step == 1 再执行 step ==2 |
path | 可选 | Huggingface 模型文件夹路径。 | 默认为 Qwen/Qwen2-VL-2B-Instruct |
batch | 可选 | batch size | 默认为 1 |
height | 可选 | 图片高度 | 默认为 392 |
width | 可选 | 图片宽度 | 默认为 392 |
savepath | 可选 | RKNN 模型保存路径 | 默认为 qwen2-vl-2b/qwen2_vl_2b_vision.onnx |
将视觉模块导出为 onnx 模型。
X64 Linux PC
pip install onnx==1.18
python export/export_vision_qwen2.py --step 2 --path ./Qwen2-VL-2B-Instruct
导出 rknn 格式的视觉模块模型,虚拟环境配置参考创建虚拟环境。
X64 Linux PC
conda activate rknn
python export/export_vision_rknn.py --path /path/to/save/qwen2-vl-vision.onnx --target-platform rk3588
生成量化校准文件。
X64 Linux PC
conda activate rkllm
python data/make_input_embeds_for_quantize.py --path /path/to/Qwen2-VL-model
| 参数 | 必要性 | 描述 | 选项 |
|---|---|---|---|
path | 必要 | Huggingface 模型文件夹路径。 | None |
导出 rkllm 格式的语言模块模型。
X64 Linux PC
python export/export_rkllm.py
| 参数 | 必要性 | 描述 | 选项 |
|---|---|---|---|
path | 可选 | Huggingface 模型文件夹路径 | 默认为 Qwen/Qwen2-VL-2B-Instruct |
target-platform | 可选 | 目标运行平台 | 可选 rk3588/rk3576/rk3562, 默认为 rk3588 |
num_npu_core | 可选 | 使用 NPU 核心个数 | rk3588 可选项为[1,2,3],rk3576 可选项为[1,2],rk3562 可选项为[1]。默认为 3 |
quantized_dtype | 可选 | RKLLM 量化类型 | rk3588 支持 “w8a8”, “w8a8_g128”, “w8a8_g256”, “w8a8_g512” 四种量化类型。rk3576 支持 “w4a16”, “w4a16_g32”, “w4a16_g64”, “w4a16_g128” 和 “w8a8” 五种量化类型。rk3562 支持 “w8a8”,“w4a16_g32”, “w4a16_g64”,“w4a16_g128” 和 “w4a8_g32” 五种量化类型。默认为 w8a8 |
device | 可选 | 模型转换时使用的设备 | 可选 cpu/cuda, 默认为 cpu |
savepath | 可选 | RKLLM 模型保存路径 | 默认为 qwen2_vl_2b_instruct.rkllm |
编译可执行文件
交叉编译工具链配置参考编译工具。
X64 Linux PC
cd deploy/
export GCC_COMPILER=/path/to/your/gcc/bin/aarch64-linux-gnu
bash build-linux.sh
生成的可执行文件在 install/demo_Linux_aarch64
板端部署
将转换成功后的模型与编译后生成的 demo_Linux_aarch64 目录传输到板端。
Device
cd demo_Linux_aarch64/
export RKLLM_LOG_LEVEL=1
export LD_LIBRARY_PATH=./lib
./demo demo.jpg ../qwen2_vl_2b_vision_rk3588.rknn ../qwen2-vl-2b-instruct_W8A8_rk3588.rkllm 2048 4096 3 "<|vision_start|>" "<|vision_end|>" "<|image_pad|>"
运行示例,输入 exit 退出。
Device
./demo demo.jpg ../qwen2_vl_2b_vision_rk3588.rknn ../qwen2-vl-2b-instruct_W8A8_rk3588.rkllm 2048 4096 3 "<|vision_start|>" "<|vision_end|>" "<|image_pad|>"
| 参数 | 必要性 | 描述 | 选项 |
|---|---|---|---|
image_path | 必要 | 图片路径 | N |
encoder_model_path | 必要 | rknn 解码模型路径 | N |
llm_model_path | 必要 | rkllm 模型路径 | N |
max_new_tokens | 必要 | 每轮最大生成 token 数 | 小于等于 max_context_len |
max_context_len | 必要 | 模型最大上下文范围 | max_context_len 必须大于 text-token-num+image-token-num+max_new_tokens |
core_num | 必要 | 使用 NPU 核心个数 | rk3588 可选项为[1,2,3],rk3576 可选项为[1,2],rk3562 可选项为[1] |
$ ./demo demo.jpg ../qwen2_vl_2b_vision_rk3588.rknn ../qwen2-vl-2b-instruct_W8A8_rk3588.rkllm 2048 4096 3
"<|vision_start|>" "<|vision_end|>" "<|image_pad|>"
I rkllm: rkllm-runtime version: 1.2.3, rknpu driver version: 0.9.8, platform: RK3588
I rkllm: loading rkllm model from ../qwen2-vl-2b-instruct_W8A8_rk3588.rkllm
I rkllm: rkllm-toolkit version: 1.2.3, max_context_limit: 4096, npu_core_num: 3, target_platform: RK3588, model_dtype: W8A8
I rkllm: Enabled cpus: [4, 5, 6, 7]
I rkllm: Enabled cpus num: 4
I rkllm: Using mrope
rkllm init success
main: LLM Model loaded in 3052.79 ms
===the core num is 3===
model input num: 1, output num: 1
input tensors:
index=0, name=onnx::Expand_0, n_dims=4, dims=[1, 392, 392, 3], n_elems=460992, size=921984, fmt=NHWC, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
output tensors:
index=0, name=4542, n_dims=2, dims=[196, 1536, 0, 0], n_elems=301056, size=602112, fmt=UNDEFINED, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
model input height=392, width=392, channel=3
main: ImgEnc Model loaded in 2362.74 ms
main: ImgEnc Model inference took 3762.45 ms
**********************可输入以下问题对应序号获取回答/或自定义输入********************
[0] <image>What is in the image?
[1] <image>这张图片中有什么?
*************************************************************************
user: 0
<image>What is in the image?
robot: The image depicts an astronaut sitting on a chair with a green beer bottle in his hand, overlooking Earth from the moon. The background shows the moon and the Earth, with stars visible in the sky.
user: 1
<image>这张图片中有什么?
robot: 这张图片展示了一位穿着宇航服的宇航员,他坐在月球表面的一块岩石上。背景是地球和星空,月亮上可以看到一些绿色的物体。宇航员手里拿着一个绿色的瓶子,似乎在庆祝或享受某种活动。整体氛围显得非常有趣和富有想象力。
测试使用图片。

性能表现如下。
| Stage | Total Time (ms) | Tokens | Time per Token (ms) | Tokens per Second |
|---|---|---|---|---|
| Prefill | 929.40 | 222 | 4.19 | 238.86 |
| Generate | 3897.42 | 60 | 64.96 | 15.39 |