AXCL Multistream YOLO
This document describes the axera-multistream-yolo project, a real-time multi-stream video YOLO detection solution based on Radxa AX-M1.
tip
This project depends on AXCL SDK and FFmpeg hardware decoding. Before proceeding, ensure you have configured:
Hardware Environment
| Item | Specification |
|---|---|
| DEVICE | Radxa AX-M1(Rock 5B+ Host) |
| NPU | AX8850(AXCL SDK V3.6.5) |
| Decode | FFmpeg 7.1(h264_axdec / hevc_axdec) |
Project Structure
axera-multistream-yolo/
├── src/ # Core implementation
│ ├── inference_engine.cpp # NPU inference wrapper(letterbox + AXCL + NMS)
│ ├── pipeline.cpp # StreamWorker × N orchestration
│ ├── stream_source.cpp # FFmpeg hardware decode(RTSP / local file)
│ └── ...
├── include/app/ # Header files
├── tools/npu_bench.cpp # NPU performance benchmark tool
├── configs/ # JSON configuration files
└── yolo26_demo/ # AXCL SDK reference implementation(for reference only)
Quick Start
Clone the repository
Host
git clone https://github.com/Ronin-1124/axera-multistream-yolo.git
cd axera-multistream-yolo/
Build
Host
mkdir build && cd build
cmake .. && make -j$(nproc)
Configure
Edit configs/app_config.json:
{
"streams": [
{ "id": 0, "url": "./data/test_videos_360P/test1.mp4", "enabled": true },
{
"id": 1,
"url": "rtsp://user:[email protected]:554/stream",
"enabled": true
}
],
"model": {
"path": "./models/yolo26n.axmodel",
"input_h": 640,
"input_w": 640
},
"output": { "display": true, "mosaic_cols": 2, "queue_depth": 4 }
}
Run
Host
LD_LIBRARY_PATH="/usr/lib/axcl/ffmpeg:/usr/lib/axcl:$LD_LIBRARY_PATH" \
./build/axera_multistream_yolo --config ./configs/app_config.json
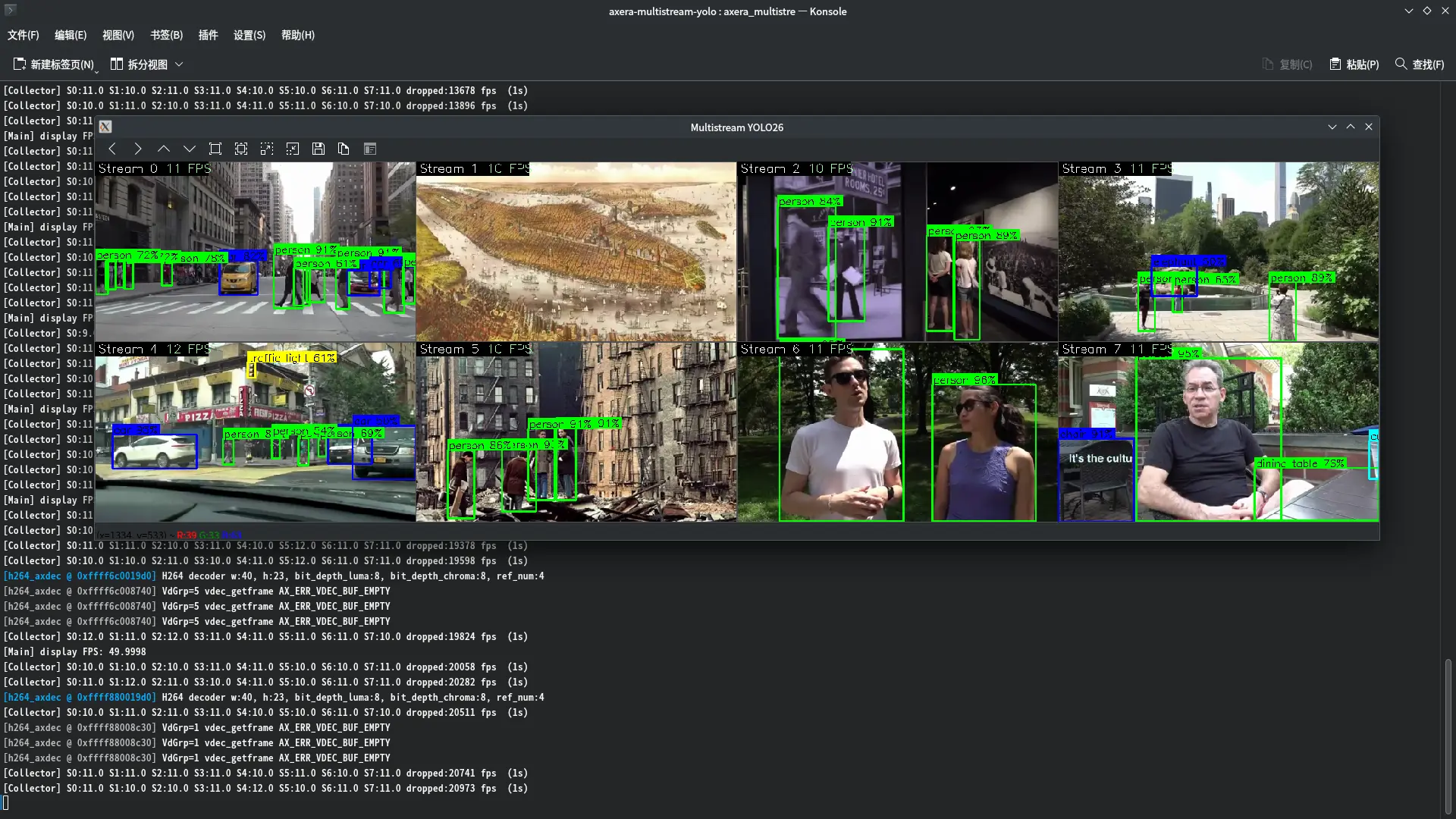
tip
When display=false, only frame rate monitoring logs are output:
[Collector] S0:14.0 S1:13.0 S2:14.0 S3:13.0 fps (1s)
[Collector] S0:15.0 S1:14.0 S2:14.0 S3:14.0 fps (1s)
NPU Performance Benchmark Tool
Host
# Stage time breakdown (H2D / NPU kernel / D2H / Post)
./build/tools/npu_bench <model> <image> --stages [N]
# Thread scalability test (1..N threads)
./build/tools/npu_bench <model> <image> --sweep <max_threads> <iters>
# Fixed thread count test
./build/tools/npu_bench <model> <image> --mt <threads> <iters>
Example:
Stage breakdown (SDK) (100 iterations, 640x640 input)
avg min max
Pre 5.69 3.82 16.86 ms
H2D 3.27 2.94 3.83 ms
NPU 1.97 1.75 2.20 ms
D2H 6.47 5.38 7.51 ms
Post 5.31 2.20 12.31 ms
Total 22.71 ms
Architecture
1:1 Fixed Ratio: Each stream = 1 read thread + 1 inference thread, fully independent.
StreamWorker × N(per stream independent)
├─ StreamSource(FFmpeg decode)→ ThreadSafeQueue → InferenceThread
└─────────────────────────────────────────────────────► ResultQueue
│
ResultCollector
└─ MosaicRenderer → imshow
Performance Data(YOLO26n,640×640)
| Configuration | Frame Rate |
|---|---|
| Single stream end-to-end | ~40 fps |
| 8-stream concurrent(mosaic) | 53-57 fps mosaic |
| AXCL multi-thread scaling | ~120 fps(plateau after 3 threads) |