Vivante NPU SDK Development Guide
- Radxa Cubie A5E
- Radxa Cubie A7A
- Radxa Cubie A7Z
The Allwinner T527 / A733 SoC is equipped with the Vivante VIP9000 series NPU。
The Vivante Machine Learning SDK is a powerful toolkit that helps developers deploy and accelerate AI inference tasks on supported boards. With hardware acceleration provided by the VIP9000 series NPU, it significantly enhances the inference performance of AI models.
The Vivante Machine Learning SDK supports various model frameworks, such as TensorFlow, TensorFlow Lite, PyTorch, Caffe, DarkNet, ONNX, and Keras. It can convert these AI models into formats that can be executed on the Vivante VIP9000 series NPU.
To deploy and infer AI models from different frameworks using the NPU, the following two steps are required:
- Parse the model structure and convert the model operators into an intermediate representation (IR).
- Compile the intermediate representation (IR) into machine-specific instructions.
Both steps can be implemented using online mode and offline mode. For better understanding, online mode is referred to as Runtime Inferencing, and offline mode is referred to as Offline Compilation.
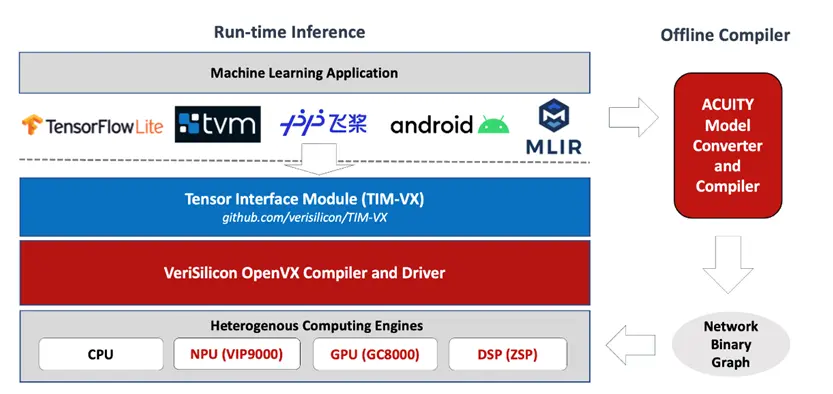
Runtime Inferencing
In Runtime Inferencing mode, users only need to focus on the original model framework without worrying about the target deployment platform. The steps of converting to intermediate representation (IR) and model compilation can run on any platform, and users do not need to maintain them. The target platform driver automatically handles the underlying acceleration, making it suitable for cross-platform software usage.
For detailed usage of Runtime Inferencing, please refer to the Vivante TIM-VX - Tensor Interface Module open-source repository.
This document does not provide detailed usage instructions for Runtime Inferencing.
Offline Compilation
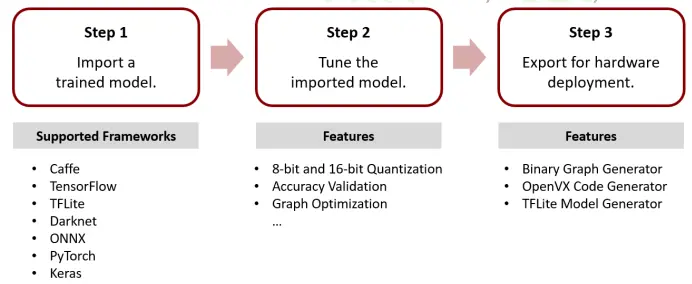
Using the ACUITY Toolkit, the original model can be compiled into a format runnable on the NPU before deployment. It supports UINT8, PCQ (INT8), INT16, BF16 quantization, and mixed quantization. During model compilation, operator fusion is automatically performed to optimize the model structure, significantly reducing model initialization time and resource overhead, making it suitable for compact embedded devices.
The ACUITY Toolkit can automatically generate cross-platform model deployment code based on the OpenVX driver and precompiled NBG model deployment code.
-
Machine Code Generator - Network Binary Graph (NBG)
NBG (Network Binary Graph) can be directly deployed on the Vivante NPU. Since NBG is already in machine code format, no further compilation is required. Instructions can be sent directly to the hardware to complete model initialization. It can run using OpenVX and VIPLite drivers.
-
Source Code Generator - OpenVX Code
The OpenVX code generator creates an OpenVX source code (C language) project that can be deployed on the Vivante NPU using OpenVX for driving. Since the generated OpenVX application is a graph-level intermediate representation (IR), the OpenVX runtime driver still needs to perform Just-In-Time (JIT) compilation when deploying to hardware devices. The advantage of this format is that it leverages model optimizations performed by offline tools while maintaining the application's cross-platform characteristics.
| NBG Project | OpenVX Project | |
|---|---|---|
| Cross-Platform Support | No | Yes |
| Just-In-Time (JIT) Compilation | No | Yes |
| Instant Model Initialization | Yes | No |
| Supports OpenVX Driver | Yes | Yes |
| Supports VIPLite Driver | Yes | No |
Mode Comparison
| Runtime Inferencing | Offline Compilation | |
|---|---|---|
| Cross-Platform Support | Yes | No |
| Easy Maintenance | Yes | No |
| Model Operator Fusion | No | Yes |
| Instant Model Initialization | No | Yes |
| Model Quantization | No | Yes |
Vivante ML Software Stack
ACUITY Toolkit
The ACUITY Toolkit is an end-to-end integrated offline development tool for model conversion, model quantization, and model compilation. ACUITY supports model conversion for various AI frameworks and can directly generate code for model execution.
TIM-VX - Tensor Interface Module
TIM-VX is a software integration module provided by VeriSilicon, designed to simplify the deployment of neural networks on its ML accelerators. It serves as a backend binding interface for runtime frameworks such as Android NN, TensorFlow Lite, MLIR, and TVM, providing efficient inference support. It is the primary online development module for Runtime Inferencing.
For detailed usage of Runtime Inferencing, please refer to the Vivante TIM-VX - Tensor Interface Module open-source repository。
This document does not provide detailed usage instructions for Runtime Inferencing。
Vivante Unified Driver
The Vivante Unified Driver provides a standardized programming interface for NPUs (Neural Processing Units). This driver stack supports industry-standard APIs such as OpenVX and OpenCL and is compatible with Linux and Android operating systems.
Vivante VIPLite Driver
The VIPLite Driver is a lightweight driver designed for embedded systems such as Linux or RTOS. It can load and run ACUITY precompiled neural network models with minimal overhead.
Unified vs. VIPLite Driver Comparison
| Feature | Unified Driver | VIPLite Driver |
|---|---|---|
| Operating Environment | Android / Linux | Android / Linux / RTOS / Bare Metal / DSP |
| Offline Compilation (NBG) | Supported | Supported |
| Runtime Just-In-Time (JIT) Compilation | Supported | Not Supported |
| Multi-VIP Support | Supported | Supported |
| Memory Usage | Tens of MB | Tens of KB |
| MMU (Memory Management Unit) Support | Supported | Supported |
| Multi-Graph Support | Supported | Supported |