QAIRT SDK Example
QAIRT provides developers with all the necessary tools for porting and deploying AI models on Qualcomm® hardware accelerators. This document details the complete process of using QAIRT to port the resnet50 object recognition model, using NPU inference on a board running Ubuntu as an example, to fully explain the method of porting models to NPU hardware using the QAIRT SDK.
Model Porting Workflow
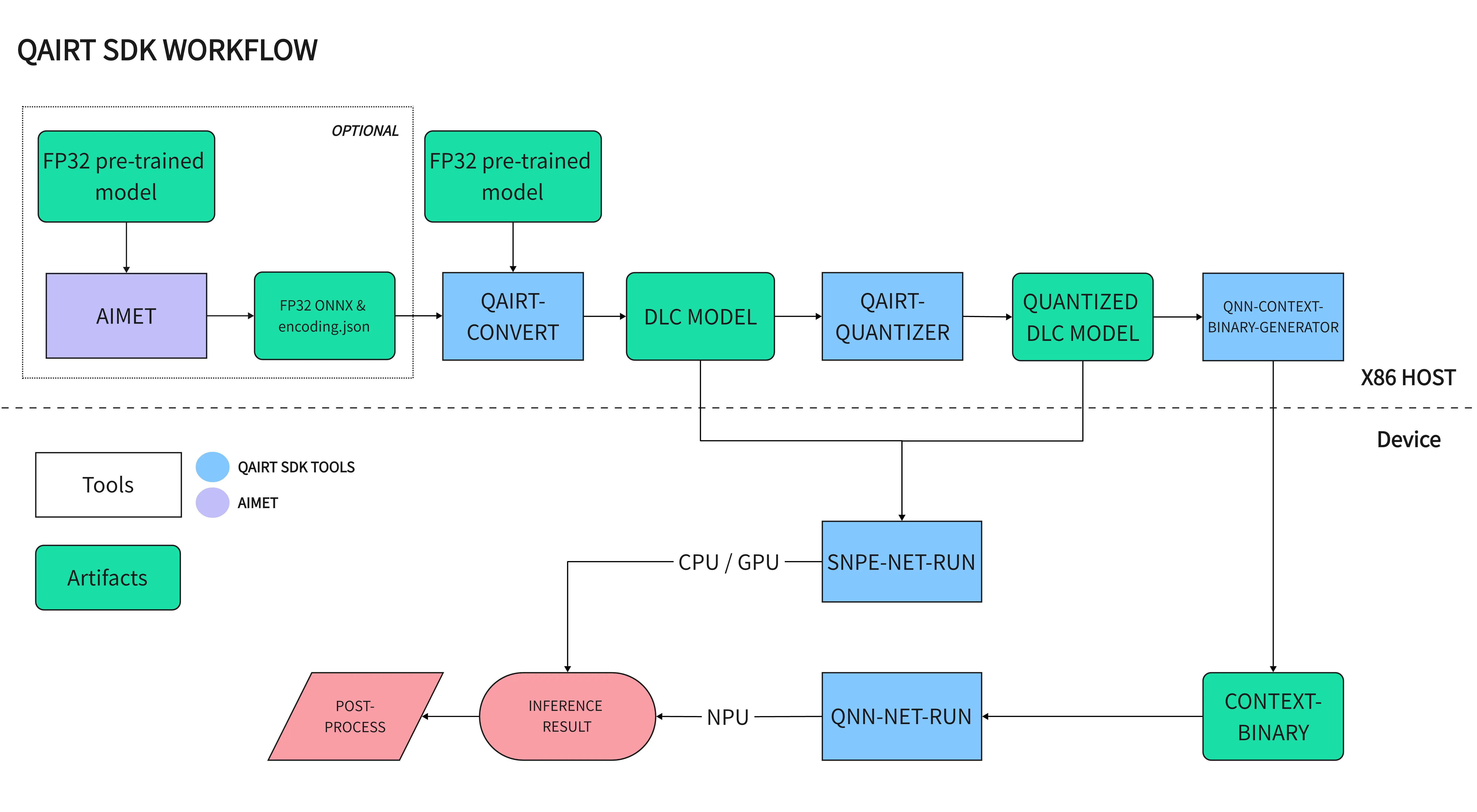
QAIRT WORKFLOW
To port mainstream AI model frameworks (PyTorch, TensorFlow, TFLite, ONNX) to Qualcomm NPU for hardware-accelerated inference, the model needs to be converted to the Context-Binary format specific to Qualcomm NPU. The following steps are required to convert to the Context-Binary format:
- Prepare a pre-trained floating-point model
- Use AIMET for efficient model optimization and quantization of the pre-trained model (optional)
- Convert the model to floating-point DLC format using QAIRT tools
- Quantize the floating-point DLC model using QAIRT tools
- Convert the DLC model to Context-Binary format using QAIRT tools
- Perform NPU inference on the Context-Binary model using QAIRT tools
The following sections use resnet50 as an example to demonstrate the complete workflow.
Part 1: Host-Side Model Conversion
Step 1: Set Up QAIRT Development Environment
Refer to QAIRT SDK Installation to set up the QAIRT working environment
Step 2: Prepare Pre-trained Model
Clone the resnet50 example repository in the QAIRT SDK
cd qairt/2.42.0.251225/examples/Models/
git clone https://github.com/ZIFENG278/resnet50_qairt_example.git && cd resnet50_qairt_example
Using PyTorch resnet50 as an example, export an ONNX model with input shape (batch_size,3,224,224). Please use the following script to export the model:
python3 export_onnx.py
The exported ONNX model is saved as resnet50.onnx
Step 3: Model Quantization with AIMET (Optional)
AIMET is an independent open-source model quantization library not included in the QAIRT SDK. Before porting the model, it is recommended to use AIMET for model optimization and quantization of pre-trained models, which can maximize the model's inference performance while maintaining its original accuracy.
Using AIMET for quantization doesn't conflict with QAIRT's quantization. AIMET provides advanced quantization, while QAIRT's quantization is standard linear quantization.
- For AIMET installation, refer to AIMET Quantization Tool
- For AIMET usage, refer to AIMET Usage Examples
Step 4: DLC Model Conversion
Using the qairt-converter in the QAIRT SDK, you can convert models from Onnx/TensorFlow/TFLite/PyTorch frameworks and AIMET output files into DLC (Deep Learning Container) model files.
qairt-converter automatically recognizes the model framework based on the file extension.
The following sections are divided into porting steps for models optimized and quantized with AIMET and original ONNX model files. Please note the distinction.
- AIMET
- Pretrained ONNX
qairt-converter --input_network ./aimet_quant/resnet50.onnx --quantization_overrides ./aimet_quant/resnet50.encodings --output_path resnet50.dlc -d 'input' 1,3,224,224
qairt-converter will generate a quantized DLC model file saved as resnet50_aimet.dlc
qairt-converter --input_network ./resnet50.onnx -d 'input' 1,3,224,224
qairt-converter will generate a floating-point DLC model file saved as resnet50.dlc
This DLC file can be used for CPU/GPU inference using the Qualcomm® Neural Processing SDK API. For details, please refer to the SNPE Documentation
For more information on using qairt-converter, please refer to qairt-converter.
Step 5: Quantizing DLC Models
DLC models obtained from AIMET models through qairt-converter are already quantized. You can skip this quantization step when using AIMET models.
NPU only supports quantized models. Before converting to the Context-Binary format, the floating-point DLC model needs to be quantized.
QAIRT provides a quantization tool qairt-quantizer that can quantize DLC models to INT8/INT16 types using quantization algorithms.
Prepare Calibration Dataset
The create_resnet50_raws.py script in the scripts directory can create raw format files for resnet50 model input to be used as quantization input
cd scripts
python3 create_resnet50_raws.py --dest ../data/calibration/crop --img_folder ../data/calibration/ --size 224
Prepare Calibration File List
The create_file_list.py script in the scripts directory can create a file list for model quantization calibration
cd scripts
python3 create_file_list.py --input_dir ../data/calibration/crop/ --output_filename ../model/calib_list.txt -e *.raw
The generated calib_list.txt contains the absolute paths to the calibration raw files
Perform DLC Model Quantization
cd model
qairt-quantizer --input_dlc ./resnet50.dlc --input_list ./calib_list.txt --output_dlc resnet50_quantized.dlc
The target quantized model is saved as resnet50_quantized.dlc. For more information on using qairt-quantizer, please refer to qairt-quantizer.
Step 6: Generate Context-Binary Model
Before using the quantized DLC model for NPU inference, the DLC model needs to be converted to the Context-Binary format. The purpose of this conversion is to prepare the instructions for running the DLC model graph on the target hardware in advance on the host. This enables inference on the NPU and reduces the model's initialization time and memory consumption on the board.
Use the qnn-context-binary-generator in the QAIRT SDK to convert the quantized DLC format model to the Context-Binary format model.
Create Model Conversion Config Files
Since hardware-specific optimization is performed on the x86 host, two config files need to be created here
SoC Architecture Reference Table
| SoC | dsp_arch | soc_id |
|---|---|---|
| QCS6490 | v68 | 35 |
| SC8280XP | v68 | 37 |
| QCS9075 | v73 | 77 |
-
config_backend.json
- QCS6490
- SC8280XP
- QCS9075
Please select the appropriate dsp_arch and soc_id based on your SoC NPU architecture. Here we use QCS6490 SoC as an example
X86 Linux PCvim config_backend.json{
"graphs": [
{
"graph_names": [
"resnet50"
],
"vtcm_mb": 0
}
],
"devices": [
{
"dsp_arch": "v68",
"soc_id": 35
}
]
}Please select the appropriate dsp_arch and soc_id based on your SoC NPU architecture. Here we use SC8280XP SoC as an example
X86 Linux PCvim config_backend.json{
"graphs": [
{
"graph_names": [
"resnet50"
],
"vtcm_mb": 0
}
],
"devices": [
{
"dsp_arch": "v68",
"soc_id": 37
}
]
}Please select the appropriate dsp_arch and soc_id based on your SoC NPU architecture. Here we use QCS9075 SoC as an example
X86 Linux PCvim config_backend.json{
"graphs": [
{
"graph_names": [
"resnet50"
],
"vtcm_mb": 0
}
],
"devices": [
{
"dsp_arch": "v73",
"soc_id": 77
}
]
}Here are 4 parameters
graph_names: The list of graph names, which are the names of the unquantized DCL model files (without suffix)vtcm_mb: A specific memory option, set the maximum VTCM to be used by the device to 0dsp_arch: NPU architecturesoc_id: SoC id -
config_file.json
X86 Linux PCvim config_file.json{
"backend_extensions": {
"shared_library_path": "libQnnHtpNetRunExtensions.so",
"config_file_path": "config_backend.json"
}
}
For detailed information on constructing the backend_extensions JSON file, please refer to qnn-htp-backend-extensions.
Generate Context-Binary
- AIMET
- Pretrained ONNX
qnn-context-binary-generator --model libQnnModelDlc.so --backend libQnnHtp.so --dlc_path resnet50.dlc --output_dir output --binary_file resnet50_quantized --config_file config_file.json
qnn-context-binary-generator --model libQnnModelDlc.so --backend libQnnHtp.so --dlc_path resnet50_quantized.dlc --output_dir output --binary_file resnet50_quantized --config_file config_file.json
The generated Context-Binary is saved in output/resnet50_quantized.bin. For more information on using qnn-context-binary-generator, please refer to qnn-context-binary-generator.
Part 2: Device-Side NPU Inference
After model conversion is complete, the following steps are executed on the target device. Using the qnn-net-run tool from the QAIRT SDK, you can perform NPU inference of the Context-Binary model on the target board. This tool serves as a testing utility for model inference.
Clone Example Repository on Target Board
cd ~/
git clone https://github.com/ZIFENG278/resnet50_qairt_example.git
Copy Required Files to Target Board
- QCS6490
- SC8280XP
- QCS9075
export PRODUCT_SOC=6490 DSP_ARCH=68
export PRODUCT_SOC=8280 DSP_ARCH=68
export PRODUCT_SOC=9075 DSP_ARCH=73
-
Copy the Context-Binary model to the target board
X86 Linux PCscp resnet50_quantized.bin <user>@<ip address>:/home/<user>/resnet50_qairt_example/model -
Copy the qnn-net-run executable to the target board
X86 Linux PCcd qairt/2.42.0.251225/bin/aarch64-oe-linux-gcc11.2
scp qnn-net-run <user>@<ip address>:/home/<user>/resnet50_qairt_example/model -
Copy the required dynamic libraries for qnn-net-run to the target board
X86 Linux PCcd qairt/2.42.0.251225/lib/aarch64-oe-linux-gcc11.2
scp libQnnHtp.so libQnnHtpV${DSP_ARCH}Stub.so <user>@<ip address>:/home/<user>/resnet50_qairt_example/model -
Copy NPU architecture-specific dynamic library files to the target board
Select the appropriate hexagon folder based on your SoC NPU architecture. Here we use QCS6490 as an example
X86 Linux PCcd qairt/2.42.0.251225/lib/hexagon-v${DSP_ARCH}/unsigned
scp ./libQnnHtpV${DSP_ARCH}Skel.so <user>@<ip address>:/home/<user>/resnet50_qairt_example/model
On-Device Inference
qnn-net-run Inference
-
Prepare Test Input Data
The Context-Binary model requires raw data as input. You need to prepare test raw data for the model input, along with an input data list.
Devicecd scripts
python3 create_resnet50_raws.py --dest ../data/test/crop --img_folder ../data/test/ --size 224
python3 create_file_list.py --input_dir ../data/test/crop/ --output_filename ../model/test_list.txt -e *.raw -r -
Execute Model Inference
Devicecd model
./qnn-net-run --backend ./libQnnHtp.so --retrieve_context ./resnet50_quantized.bin --input_list ./test_list.txt --output_dir output_binThe results are saved in the
output_bindirectory. For more information on usingqnn-net-run, please refer to qnn-net-run.
Result Verification
You can use a Python script to verify the results
cd scripts
python3 show_resnet50_classifications.py --input_list ../model/test_list.txt -o ../model/output_bin/ --labels_file ../data/imagenet_classes.txt
$ python3 show_resnet50_classifications.py --input_list ../model/test_list.txt -o ../model/output_bin/ --labels_file ../data/imagenet_classes.txt
Classification results
../data/test/crop/ILSVRC2012_val_00003441.raw 21.740574 402 acoustic guitar
../data/test/crop/ILSVRC2012_val_00008465.raw 23.423716 927 trifle
../data/test/crop/ILSVRC2012_val_00010218.raw 12.623559 281 tabby
../data/test/crop/ILSVRC2012_val_00044076.raw 18.093769 376 proboscis monkey
By comparing the printed results with the test images, we can confirm that the resnet50 model has been successfully ported to the Qualcomm® NPU with correct output.

ResNet50 Input Images