RKLLM Qwen2-VL
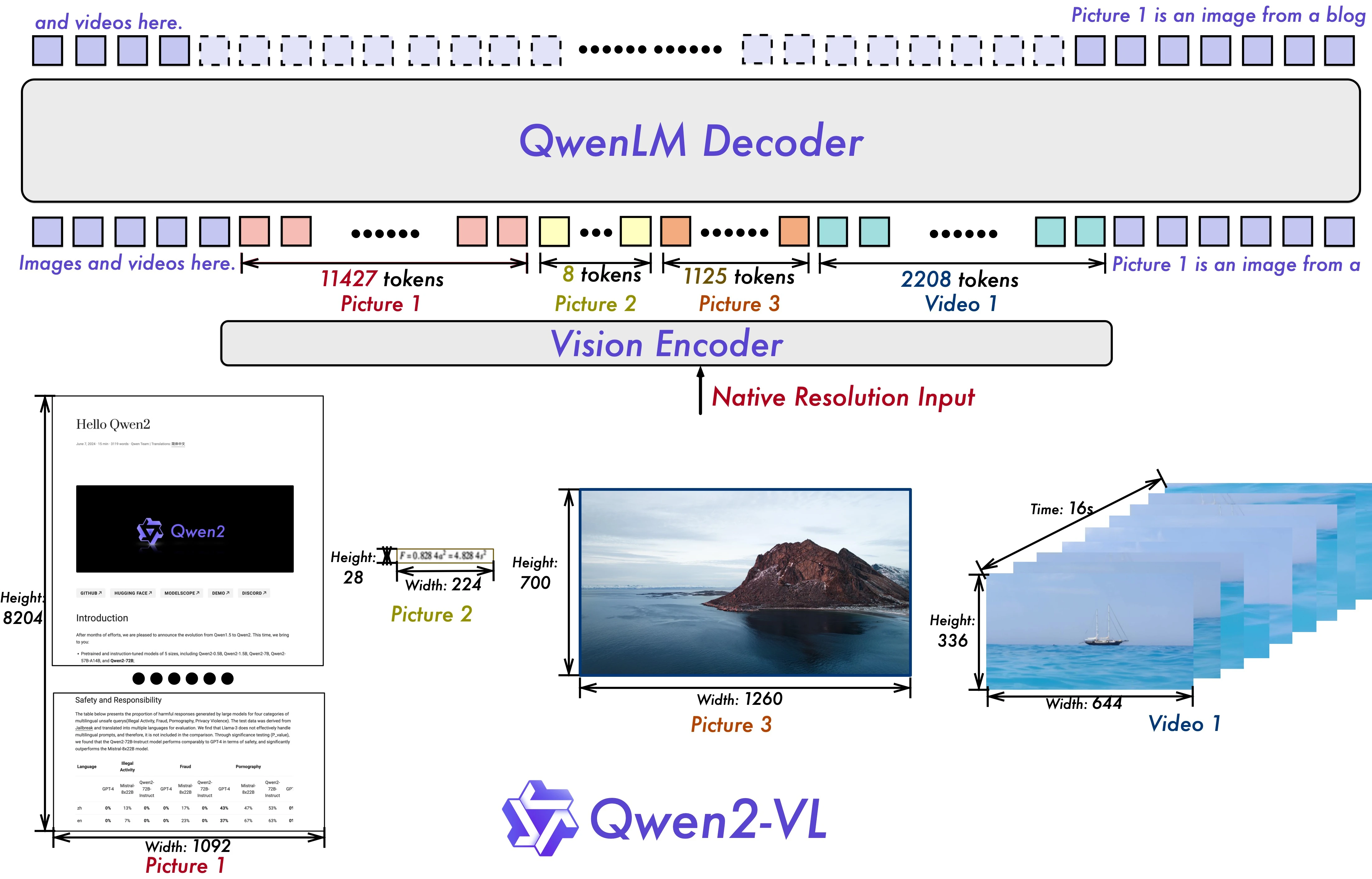
Qwen2-VL is a multi-modal VLM model developed by Alibaba.
Qwen2-VL can understand images of various resolutions and aspect ratios, comprehend videos longer than 20 minutes, function as an agent for operating mobile devices and robots, and supports multiple languages.
This document will explain how to deploy the Qwen2-VL-2B-Instruct visual multi-modal model on RK3588 using NPU for hardware-accelerated inference.
Model File Download
Radxa has provided precompiled rkllm models and executables, which users can download and use directly. If you want to refer to the compilation process, please continue with the optional section.
-
Use git LFS to download the precompiled rkllm from ModelScope:
X86 Linux PCgit lfs install
git clone https://www.modelscope.cn/radxa/Qwen2-VL-2B-RKLLM.git
(Optional) Model Compilation
Please prepare the RKLLM working environment on both your PC and development board according to RKLLM Installation.
For RK358X users, please specify the rk3588 platform for TARGET_PLATFORM.
-
On x86 PC workstation, download the Qwen2-VL-2B-Instruct weight files. If you haven't installed git-lfs, please install it first:
X86 Linux PCgit lfs install
git clone https://huggingface.co/Qwen/Qwen2-VL-2B-Instruct -
Activate the rkllm conda environment. You can refer to RKLLM conda installation for details:
X86 Linux PCconda activate rkllm
Compile Image Decoding Model
-
Install rknn-toolkit2:
X86 Linux PCpip3 install rknn-toolkit2 -i https://mirrors.aliyun.com/pypi/simple -
Convert to ONNX
-
Generate cu_seqlens and rotary_pos_emb
X86 Linux PCpython3 export/export_vision.py --step 1 --path /path/to/Qwen2-VL-2B-Instruct/ --batch 1 --height 392 --width 392 -
Export as ONNX
X86 Linux PCpython3 export/export_vision.py --step 2 --path /path/to/Qwen2-VL-2B-Instruct/ --batch 1 --height 392 --width 392
Parameter Name Required Description Options stepRequired Export step. 1/2, When step==1, only generates cu_seqlens and rotary_pos_emb; whenstep==2, exports ONNX. Must runstep == 1beforestep == 2.pathOptional Path to Huggingface model folder. Default: Qwen/Qwen2-VL-2B-InstructbatchOptional Batch size Default: 1 heightOptional Image height Default: 392 widthOptional Image width Default: 392 savepathOptional Save path for RKNN model Default: qwen2-vl-2b/qwen2_vl_2b_vision.onnx -
Compile RKLLM Model
-
Generate VLM model quantization calibration file:
X86 Linux PCcd rknn-llm/examples/Qwen2-VL_Demo
python3 data/make_input_embeds_for_quantize.py --path /path/to/Qwen2-VL-2B-InstructParameter Required Description Options pathRequired Path to Huggingface model folder. N The generated calibration file is saved in
data/input.json. -
Modify the maximum context value
max_contextIf you need to adjust the
max_contextlength, modify themax_contextparameter in thellm.buildfunction interface inrknn-llm/examples/Qwen2-VL_Demo/export/export_rkllm.py. Larger values consume more memory. It must not exceed 16,384 and must be a multiple of 32 (e.g., 32, 64, 96, ..., 16,384). -
Run the model conversion script:
X86 Linux PCpython3 export_rkllm.py --path /path/to/Qwen2-VL-2B-Instruct/ --target-platform rk3588 --num_npu_core 3 --quantized_dtype w8a8 --device cuda --savepath ./qwen2-vl-llm_rk3588.rkllmParameter Required Description Options pathOptional Path to Huggingface model folder. Default: Qwen/Qwen2-VL-2B-Instructtarget-platformOptional Target running platform rk3588/rk3576/rk3562, default:rk3588num_npu_coreOptional Number of NPU cores For rk3588: [1,2,3];rk3576: [1,2];rk3562: [1]. Default:3quantized_dtypeOptional RKLLM quantization type rk3588: “w8a8”, “w8a8_g128”, “w8a8_g256”, “w8a8_g512”;rk3576: “w4a16”, “w4a16_g32”, “w4a16_g64”, “w4a16_g128”, “w8a8”;rk3562: “w8a8”, “w4a16_g32”, “w4a16_g64”, “w4a16_g128”, “w4a8_g32”. Default:w8a8deviceOptional Device used during model conversion cpuorcuda. Default:cpusavepathOptional Save path for RKLLM model Default: qwen2_vl_2b_instruct.rkllmThe generated RKLLM model is named
qwen2-vl-llm_rk3588.rkllm.
(Optional) Build Executable
-
Download the cross-compilation toolchain gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu
-
Modify the main program
rknn-llm/examples/Qwen2-VL_Demo/deploy/src/main.cppYou need to comment out line 179. When converting the model, RKLLM will automatically parse the
chat_templatefield in thetokenizer_config.jsonfile of the Hugging Face model, so there's no need to modify it.CPP Code179 // rkllm_set_chat_template(llmHandle, "<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n", "<|im_start|>user\n", "<|im_end|>\n<|im_start|>assistant\n"); -
Modify the main program
rknn-llm/examples/Qwen2-VL_Demo/deploy/src/llm.cppYou need to comment out line 120. When converting the model, RKLLM will automatically parse the
chat_templatefield in thetokenizer_config.jsonfile of the Hugging Face model, so there's no need to modify it.CPP Code120 // rkllm_set_chat_template(llmHandle, "<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n", "<|im_start|>user\n", "<|im_end|>\n<|im_start|>assistant\n"); -
Modify the
GCC_COMPILER_PATHin the compilation scriptrknn-llm/examples/Qwen2-VL_Demo/deploy/build-linux.shBASH5 GCC_COMPILER_PATH=/path/to/gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu -
Run the model conversion script
X86 Linux PCcd rknn-llm/examples/Qwen2-VL_Demo/deploy
bash build-linux.shThe generated executable file is located in
install/demo_Linux_aarch64
Deploying on Device
Terminal Mode
-
Copy the converted model
qwen2-vl-llm_rk3588.rkllmand the compiled folderdemo_Linux_aarch64to the device -
Set environment variables
Radxa OSexport LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/demo_Linux_aarch64/libtipUsers who downloaded via ModelScope can directly
exportthelibrkllmrt.sofrom the downloaded repository. -
Run
llm_demo, enterexitto quitRadxa OSexport RKLLM_LOG_LEVEL=1
## Usage: ./demo image_path encoder_model_path llm_model_path max_new_tokens max_context_len core_num
./demo demo.jpg ./qwen2_vl_2b_vision_rk3588.rknn ./qwen2-vl-llm_rk3588.rkllm 128 512 3Parameter Required Description Options image_pathRequired Path to input image N/A encoder_model_pathRequired Path to rknn vision encoder model N/A llm_model_pathRequired Path to rkllm model N/A max_new_tokensRequired Max number of tokens to generate per round Must be ≤ max_context_len max_context_lenRequired Maximum context length for the model Must be > text-token-num + image-token-num + max_new_tokens core_numRequired Number of NPU cores to use For rk3588: [1,2,3], Forrk3576: [1,2], Forrk3562: [1]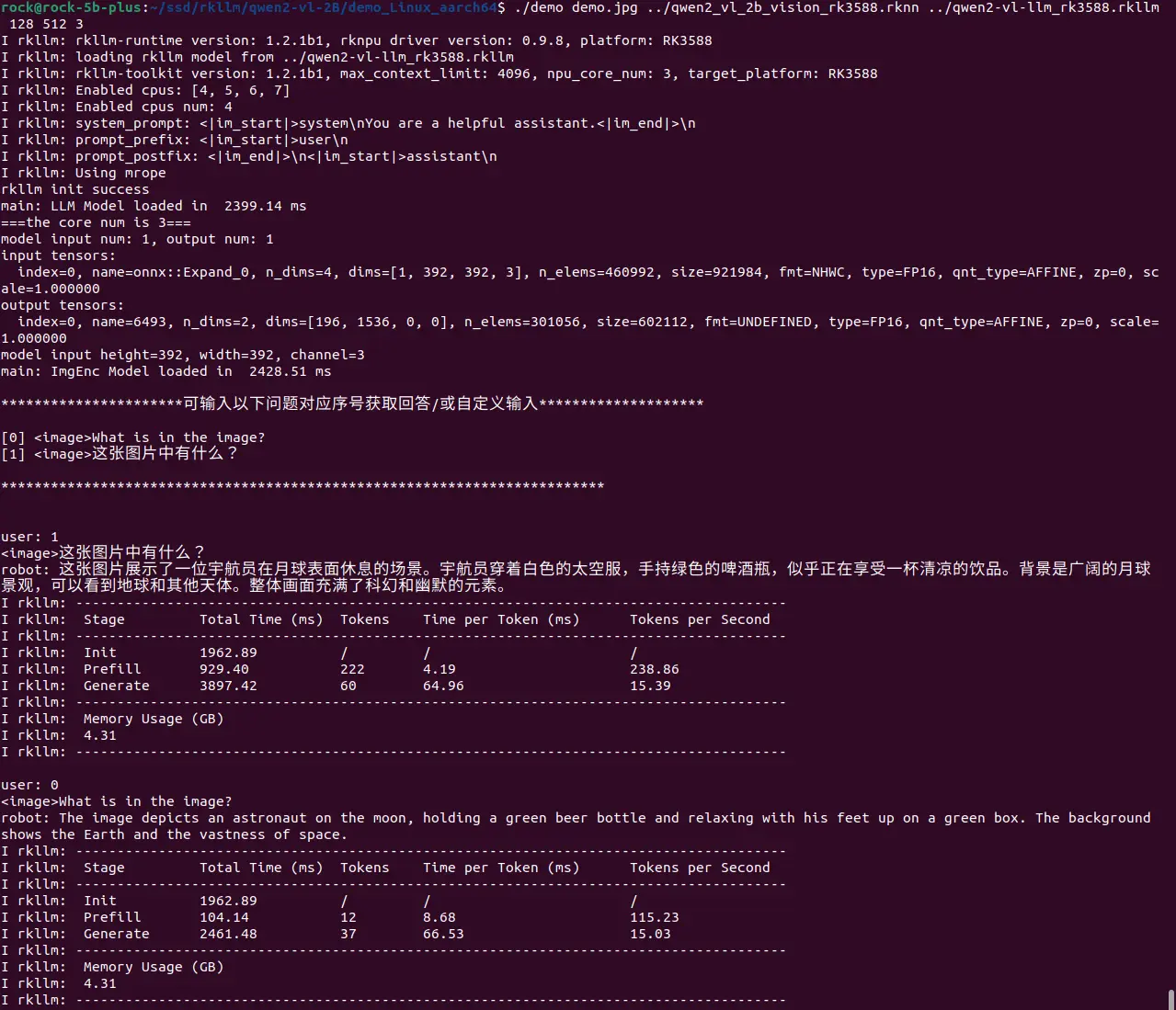
Performance Analysis
On RK3588, up to 15.39 tokens/s,
| Stage | Total Time (ms) | Tokens | Time per Token (ms) | Tokens per Second |
|---|---|---|---|---|
| Prefill | 929.40 | 222 | 4.19 | 238.86 |
| Generate | 3897.42 | 60 | 64.96 | 15.39 |