Whisper-TPU
Whisper-TPU is an application that uses the open-source Whisper model from OpenAI. It is ported to the SG2300X chip series products using the Sophon SDK, enabling hardware-accelerated inference on local TPU. This application can quickly convert speech to text (STT) and will integrate with ChatGLM2 in the future to understand and translate speech content. The application provides a user-friendly interface using Gradio.
-
Clone the repository and switch to the release branch:
git clone https://github.com/zifeng-radxa/whisper-TPU_py -b release -
Download the Whisper bmodel:
cd whisper-TPU_py
wget https://github.com/radxa-edge/TPU-Edge-AI/releases/download/Whisper/tar_downloader.sh
bash tar_downloader.sh
tar -xvf Whisper_bmodel.tar.gz -
Move the downloaded Whisper bmodel to the whisper-TPU_py/bmodel directory:
mv Whisper_bmodel/bmodel/ .The resulting file structure will be as follows:
.
├── chatglm-int8-1024
└── whisper-TPU_py
├── Whisper_bmodel
├── bmodel
├── bmwhisper
│ ├── assets
│ ├── normalizers
│ └── third_party
│ └── untpu
│ └── lib
└── test -
Set up a virtual environment:
It is necessary to create a virtual environment to avoid potential interference with other applications. For virtual environment usage, please refer to this guide.
cd whisper-TPU_py
python3 -m virtualenv .venv
source .venv/bin/activate -
Install dependencies:
pip3 install --upgrade pip
pip3 install -r requirements.txt
python3 setup.py install -
Run in CLI mode:
export LOG_LEVEL=-1
export LD_LIBRARY_PATH=/opt/sophon/libsophon-current/lib:$LD_LIBRARY_PATH
bmwhisper ./test/demo.wav --model base --bmodel_dir ./bmodel/ --chip_mode socExplanation of parameters:
audio(required): Input audio file--model: Select model [base, small, medium]--bmodel_dir: Specify the bmodel directory--chip_mode: Run platform mode [soc, pcie]
-
Run in Web mode:
-
Clone the Whisper-WebUI repository in the same directory as whisper-TPU_py:
git clone https://github.com/zifeng-radxa/Whisper-WebUIThe resulting file structure will be as follows:
├── Whisper-WebUI
├── chatglm-int8-1024
└── whisper-TPU_py -
Install gradio in the virtual environment .venv in whisper-TPU_py:
cd Whisper-WebUI
pip3 install -r requirements.txt -
Configure the path of the chatglm2 model to be used in the config.ini file. The default is chatglm2-int8-1024:
[llm_model]
libtpuchat_path = ../chatglm-int8-1024/libtpuchat.so
bmodel_path = ../chatglm-int8-1024/w8a16_chatglm2-6b_1024.bmodel
token_path = ../chatglm-int8-1024/tokenizer.model -
Start the web service:
python3 main.py -
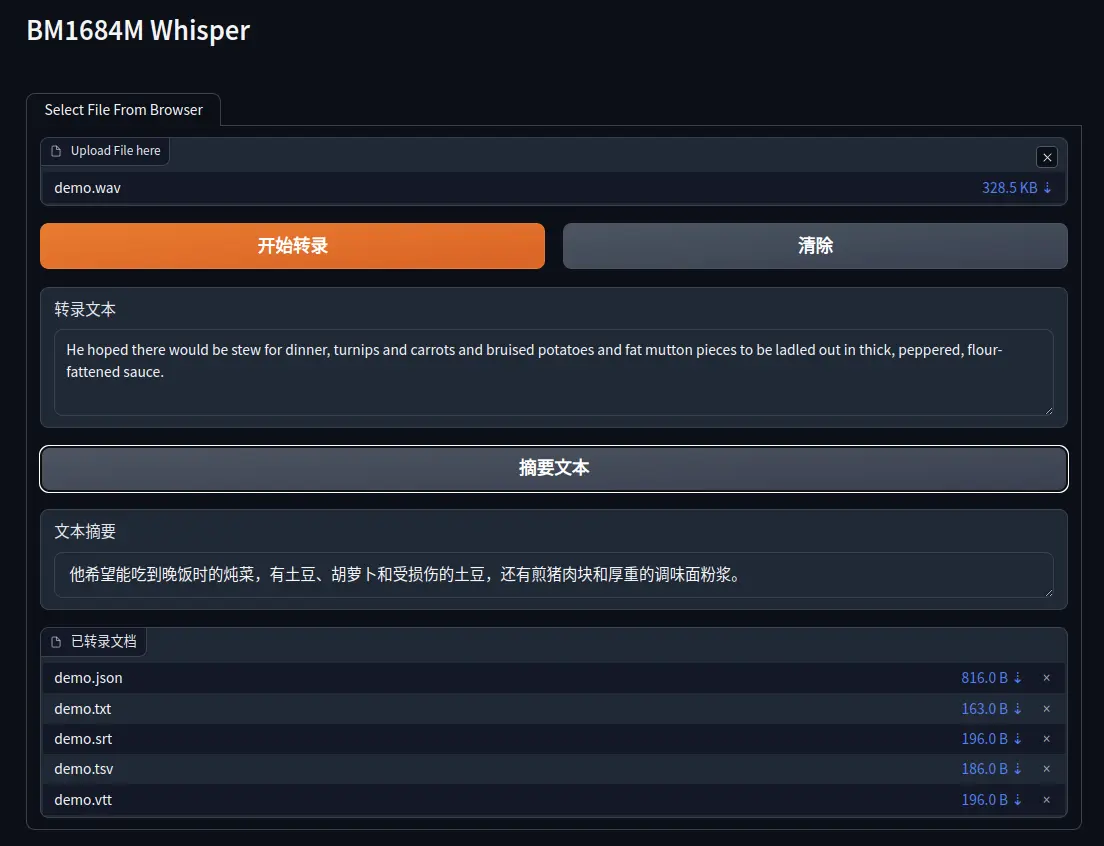
Access the 7860 port of the Airbox IP address in the browser.
-
Application Display
TPU bmodel init time: 2.6767737865448s
============================================== Start ===============================================
### audio_path: demo.wav
Detecting language using up to the first 30 seconds. Use `--language` to specify the language
Detected language: English
[00:00.000 --> 00:05.600] He hoped there would be stew for dinner, turnips and carrots and bruised potatoes and fat
[00:05.600 --> 00:10.200] mutton pieces to be ladled out in thick, peppered flour-fatten sauce.
Total tpu inference time: 1.0039873123168945s
Total cpu inference time: 2.4082088470458984s
Total time: 3.412196159362793s
----------------------------- Total time: 6.1094677448272705 seconds ------------------------------