Stable Diffusion-TPU
Stable Diffusion is a generative model that can create scene photos based on text or images. The open-source StableDiffusion 1.5 model has been ported to the SG2300X chip series for local TPU hardware accelerated inference via the Sophon SDK. By combining the LCM Lora acceleration module and style LoRa, you can quickly generate images with distinctive styles, and use Gradio for user interaction.
Application Deployment
-
Clone the repository and switch to the
radxa_v0.3.0branchgit clone https://github.com/zifeng-radxa/SD-lcm-tpu.git -
Download the Stable Diffusion models package provided by Radxa
Currently, the precompiled bmodels available are:
Users can also compile any Stable Diffusion v1.5 checkpoints by referring to Model Conversion.
cd SD-lcm-tpu
mkdir -p models/basic && cd models/basic
# AbsoluteReality bmodels
wget https://github.com/radxa-edge/TPU-Edge-AI/releases/download/sd_v3/tar_downloader.sh
bash tar_downloader.sh
tar -xvf AbsoluteReality_v1.8.1_sd15_original.tar.gz
# Controlnet
cd SD-lcm-tpu
mkdir -p models/controlnet && cd models/controlnet
wget https://github.com/radxa-edge/TPU-Edge-AI/releases/download/sd_v3/canny_multize.bmodel -
Configure the environment
You must create a virtual environment to avoid affecting other applications. For virtual environment usage, please refer to here.
cd SD-lcm-tpu
python3 -m virtualenv .venv
source .venv/bin/activate -
Install dependencies
pip3 install --upgrade pip
pip3 install -r requirements.txt -
Start the Web service
bash run.sh -
Access port 8999 of the Airbox IP address using a browser
Application Showcase
Text-to-Image
Prompt
upper body photo, fashion photography of cute Hatsune Miku,
very long turquoise pigtails and a school uniform-like outfit.
She has teal eyes and very long pigtails held with black and
red square-shaped ribbons that have become a signature of her design,
moonlight passing through hair.
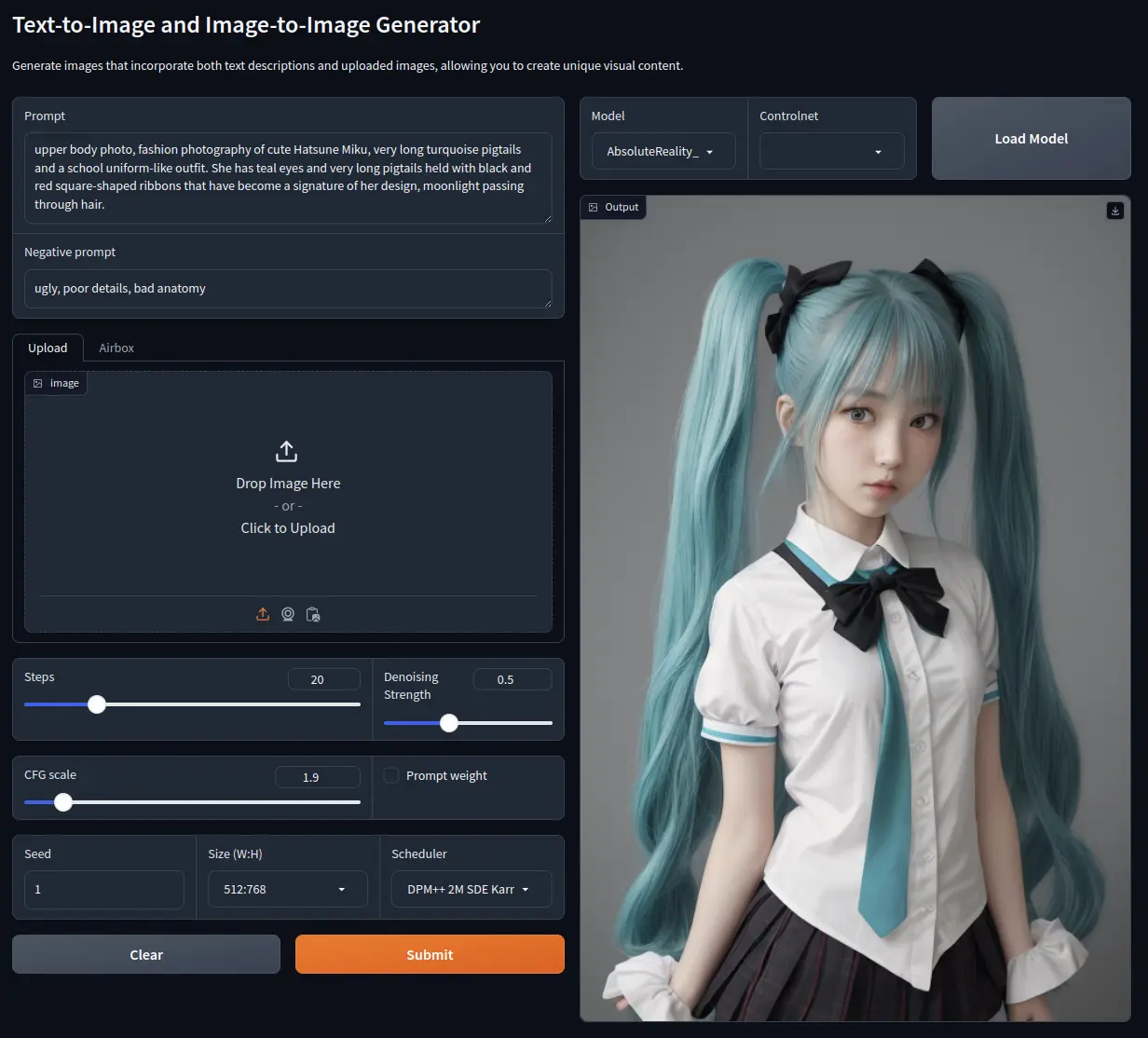
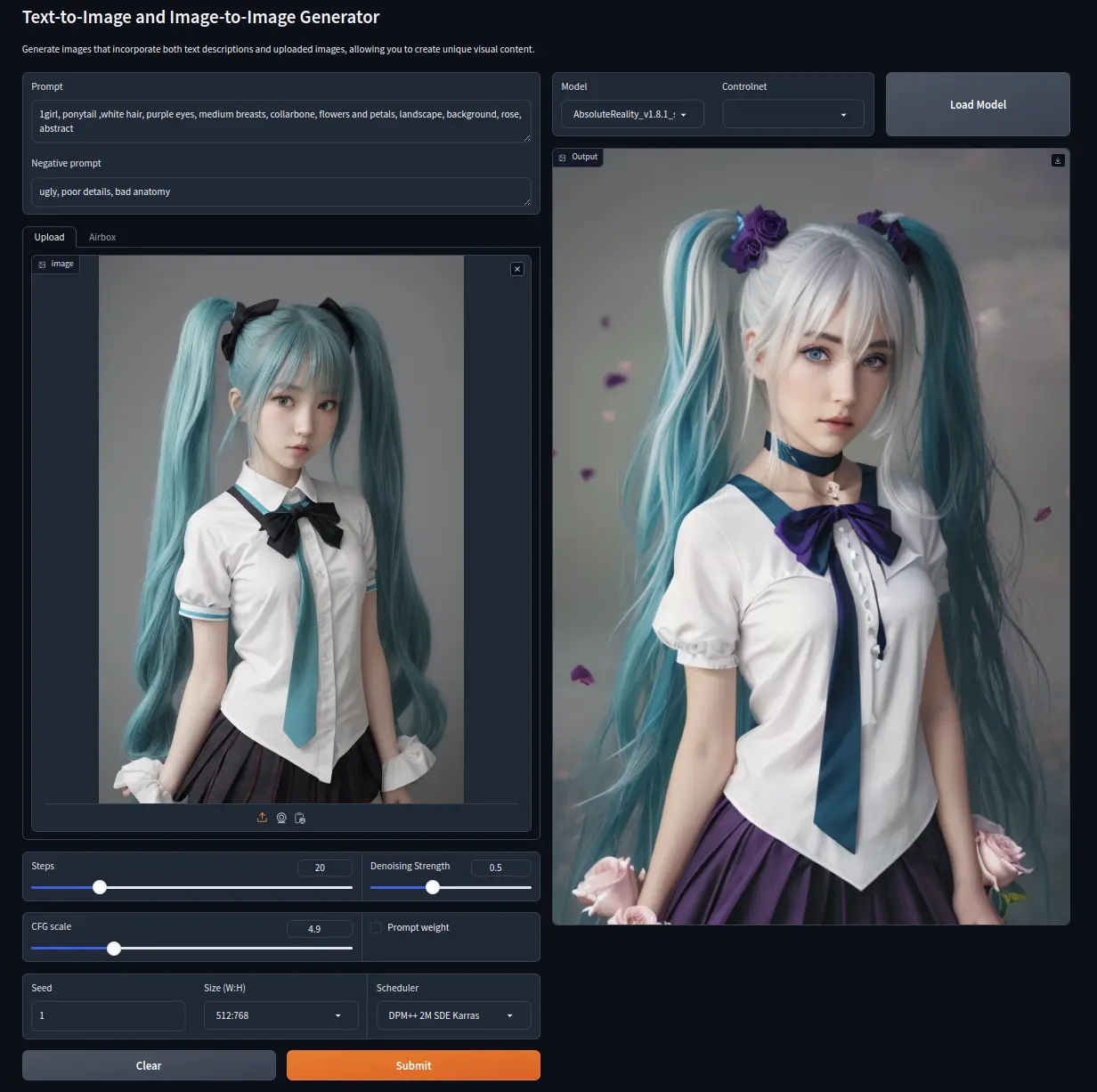
Image-to-Image
Prompt
1girl, ponytail, white hair, purple eyes, medium breasts, collarbone,
flowers and petals, landscape, background, rose, abstract
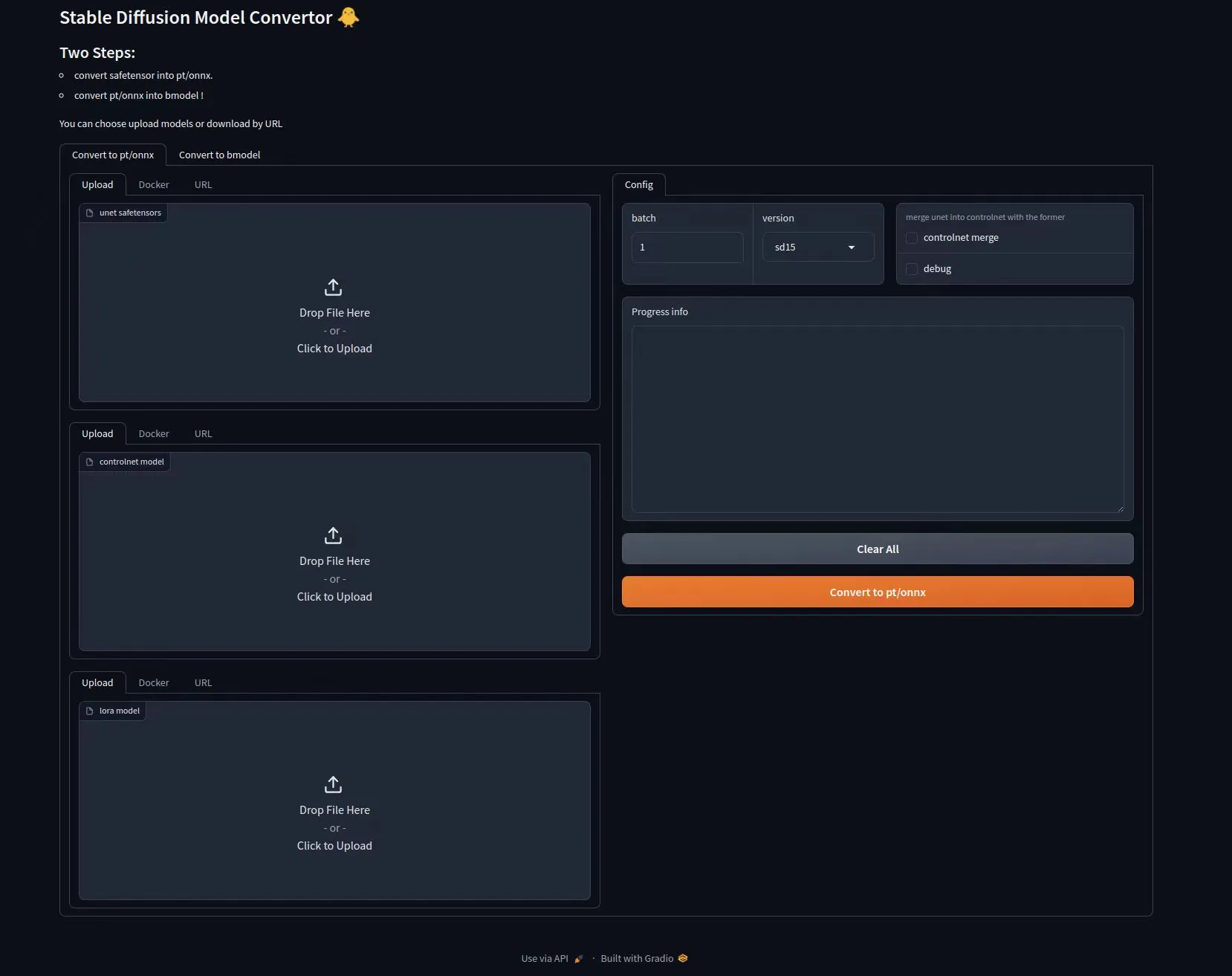
Model Conversion
Users can refer to this section to convert any Stable Diffusion 1.5 models. You can download models from Civitai.
Currently, there are two conversion modes available: Command Line Mode Conversion and WebUI Interactive Mode Conversion.
Environment Preparation
-
x86 Workstation Environment Preparation
Refer to TPU-MLIR Installation to configure the TPU-MLIR environment.
Create a Docker container
docker run --privileged --name myname -p 8088:7860 -v $PWD:/workspace -it sophgo/tpuc_dev:latest -
Configure the environment
Clone the project repository
git clone https://github.com/zifeng-radxa/SD-lcm-tpu.gitDownload the lcm-lora-sdv1-5 Lora model files from Huggingface into the working directory
git clone https://huggingface.co/latent-consistency/lcm-lora-sdv1-5Install dependency libraries
cd SD-lcm-tpu/model_export
pip3 install --upgrade pip
pip3 install https://github.com/radxa-edge/TPU-Edge-AI/releases/download/v0.1.0/tpu_mlir-1.6.404-py3-none-any.whl
pip3 install -r requirements.txt
Command Line Mode Conversion
-
Convert the model from safetensor to pt/onnx
python3 export_from_safetensor_sd15_cli_wrapper.py -u xxxxx/model.safetensor -l xxxx/lora.safetensor -c xxxx/controlnet.safetensor -b 1 -o xxxxx/name-u: Path to the safetensors file of the model to be converted-l: (Optional) Path to the lora file-c: (Optional) Path to the controlnet fileIf you want to use LCM to reduce the number of diffusion steps required to generate high-quality images, specify the
-lparameter with the path to thelcm-lora-sdv1-5folder; otherwise, the generated model may require around 20 steps for the same quality of images.The model will be saved to the directory specified by
-o..
├── text_encoder
│ └── text_encoder.onnx
├── unet
│ └── unet_fuse_1.pt
├── vae_decoder
│ └── vae_decoder.pt
└── vae_encoder
└── vae_encoder.pt -
Convert pt/onnx to bmodel
python3 convert_bmodel_cli_wrapper.py -n xxxxx/name -o xxxxx -s 512 512 768 512 512 768 -b 1 -v sd15-n: Path to the folder generated in the first step-s: Input size, supports multiple sizes latent-o: (Optional) Target directory pathThe resulting bmodel will be in the directory specified by
-o..
├── sdv15_text.bmodel
├── sdv15_unet_multisize.bmodel
├── sdv15_vd_multisize.bmodel
└── sdv15_ve_multisize.bmodelCopy this folder to the
SD-lcm-tpu/models/basicfolder on the Airbox.
WebUI Interactive Mode Conversion
Start the model converter service in Docker, then use a browser to access port 8088 of the host running this Docker container.
python3 gr_docker.py
-
Step 1: Convert safetensor to onnx/pt format models
-
Supports browser upload
-
Supports selecting files within the container
-
Supports URL auto-download (refer to here for obtaining Civitai API token)
-
-
Step 2: Convert onnx/pt format models to bmodel
-
Refresh the page
-
Select the folder path generated in Step 1, the parent directory of the onnx/pt model
-