介绍
硬件
Genio 概念
NIO 12L 使用的 SoC 是 Genio 1200,Genio 是联发科(Mediatek)用于物联网平台的 SoC 系列名称。
Genio 1200 结构
Genio 1200 可用于 AI 加速的硬件:
| 硬件 | 型号 | 说明 |
|---|---|---|
| GPU | Arm Mali-G57 MC5 | 提供浮点模型加速 |
| NPU | 2xMDLA2.0 + 2xVP6 | 神经网络处理单元 |
NPU 是 MDLA 和 VPU 的统称。NPU 内部分为大中小规模的核心,这种异构设计提供了对各种类型 AI 的支持。
MDLA 说明
MDLA 全称是 Mediatek Deep Learning Accelerator,即深度学习加速器。主要用于卷积神经网络加速。
限制说明
MDLA2.0 不支持循环神经网络及基于 Transformer 的生成式大模型。
部署
总览
Genio AI 软件栈支持分析式 AI 和生成式 AI,均使用 host-device 的架构,即在主机上转换量化模型,然后在设备上运行处理好的模型。
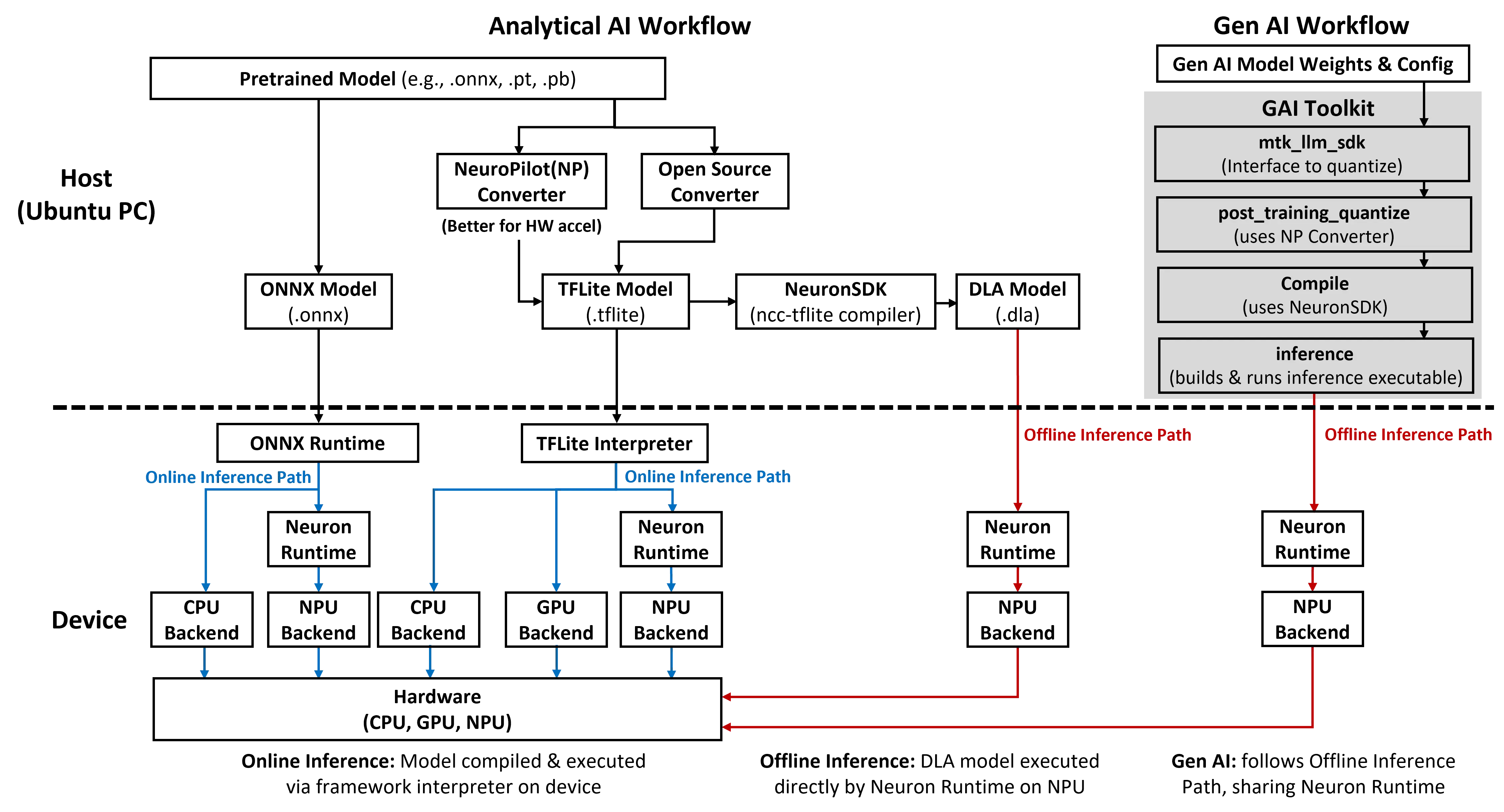
两种模式
设备上运行的推理模式分为 online 和 offline 两种:
| 模式 | 推理框架 | 模型格式 |
|---|---|---|
| online | 通用 AI 框架(TFlite、ONNX) | tflite、onnx |
| offline | Neuron Runtime | dla |
核心区别在于是否需要在设备端配置通用 AI 框架的推理解析工具。两种模式都需要配置 NPU 的 Neuron Runtime,因为通用 AI 框架的推理解析工具在调用 NPU 时也是通过 Neuron Runtime 调用的。
online 模式
该模式适合模型能够高效利用异构框架的场景。
分析式 AI - online 模式硬件调度
| 框架 | 支持的硬件 |
|---|---|
| ONNX Runtime | CPU、NPU |
| TFlite Interpreter | CPU、GPU、NPU |
针对 tflite 格式的模型,联发科提供了专用的转换工具 NeuroPilot Converter,对硬件加速更友好。
生成式 AI
限制
目前只有 offline 模式,仅用于教学目的。Genio 1200 暂不支持生成式 AI。
生成式 AI 部署流程
- 通过
mtk_llm_sdk工具量化模型 - 用
post_training_quantize工具转换为 tflite 格式 - 用 NeuroPilot Converter 转换为 dla 格式
- 编译为可执行程序,推送到设备端执行
- 设备端通过 Neuron Runtime 在 NPU 上运行
软件栈
NeuroPilot
NeuroPilot(NP)是联发科用于 AI 开发的工具、文档、运行时及接口集合。
版本说明
对于一个 SoC,生命周期能使用的 NP 版本是固定的,因为硬件在设计之初支持的算子类型已经固定。
- MDLA2.0 的 2.0 标识了它的版本号
- NP 的版本需要和 MDLA 硬件的版本匹配
Genio 1200 支持情况
| 功能 | 支持状态 |
|---|---|
| 分析式 AI (online) | TFlite ✅ / ONNX ❌ |
| 分析式 AI (offline) | ✅ |
| 生成式 AI | ❌ |