Stable Diffusion-TPU
Stable Diffusion 是一个可以根据文本/图片生成相应场景照片的生成式大模型,目前使用 StableDiffusion 1.5 开源模型通过 sophon SDK 移植到 SG2300X 芯片系列产品上进行本地 TPU 硬件加速推理,可以结合 LCM Lora 加速模块与风格 LoRa 实现快速推理生成特色风格图片,并使用 Gradio 实现用户交互
应用部署
-
克隆仓库并切换成 radxa_v0.3.0 分支
git clone https://github.com/zifeng-radxa/SD-lcm-tpu.git -
下载 radxa 提供的 Stable Diffusion models 压缩包
目前提供的预编译 bmodel 有:
用户也可通过参考 模型转换 编译任何 stable_diffusion v1.5 checkpoints
cd SD-lcm-tpu
mkdir -p models/basic && cd models/basic
# AbsoluteReality bmodels
wget https://github.com/radxa-edge/TPU-Edge-AI/releases/download/sd_v3/tar_downloader.sh
bash tar_downloader.sh
tar -xvf AbsoluteReality_v1.8.1_sd15_original.tar.gz
# Controlnet
cd SD-lcm-tpu
mkdir -p models/controlnet && cd models/controlnet
wget https://github.com/radxa-edge/TPU-Edge-AI/releases/download/sd_v3/canny_multize.bmodel -
配置环境
必须创建虚拟环境,否则可能会影响其他应用的正常运行, 虚拟环境使用请参考这里
cd SD-lcm-tpu
python3 -m virtualenv .venv
source .venv/bin/activate -
安装依赖
pip3 install --upgrade pip
pip3 install -r requirements.txt -
启动 Web 服务
bash run.sh -
浏览器访问 Airbox ip 地址的 8999 端口
应用展示
Text-to-Image
Prompt
upper body photo, fashion photography of cute Hatsune Miku,
very long turquoise pigtails and a school uniform-like outfit.
She has teal eyes and very long pigtails held with black and
red square-shaped ribbons that have become a signature of her design,
moonlight passing through hair.
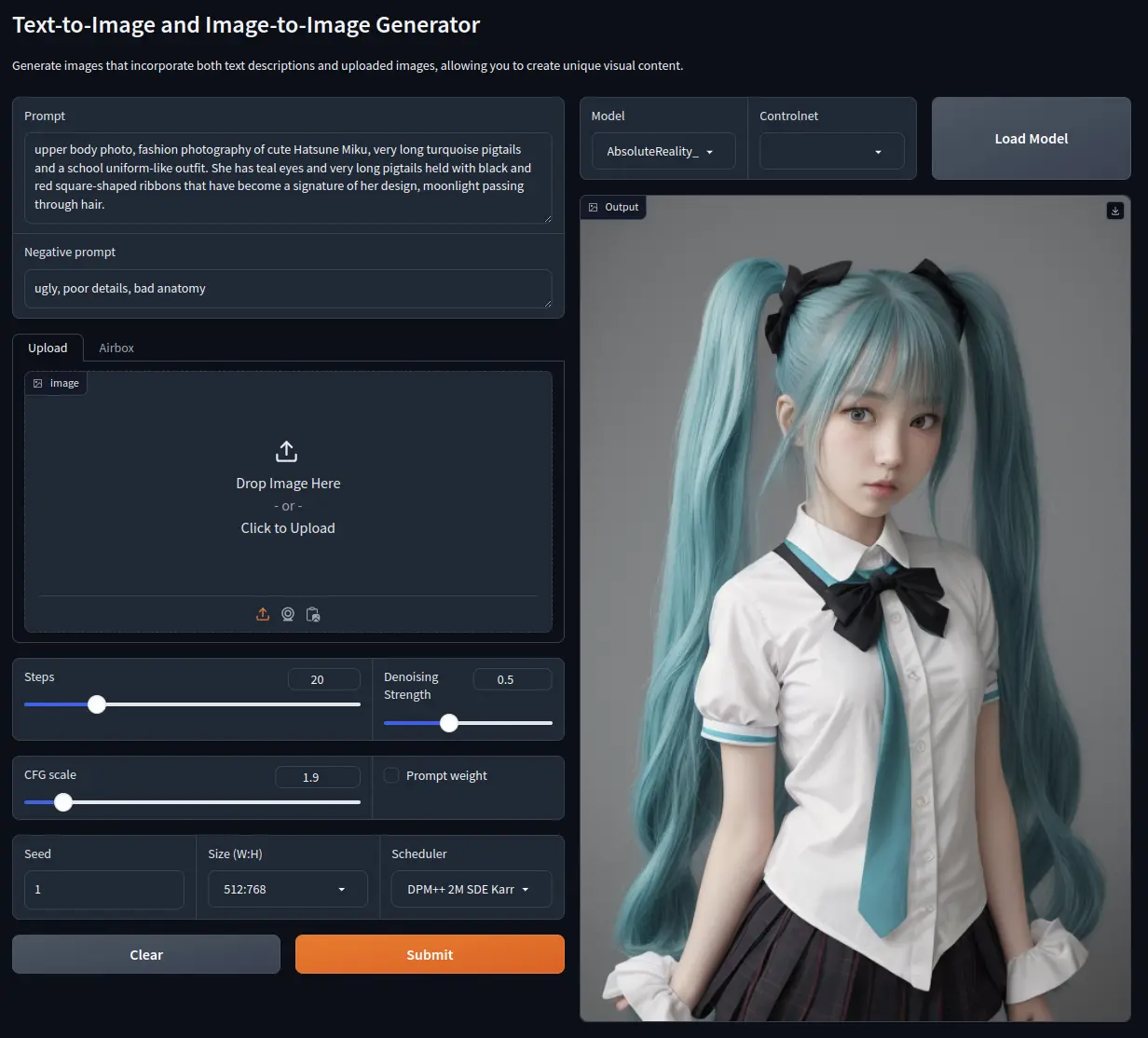
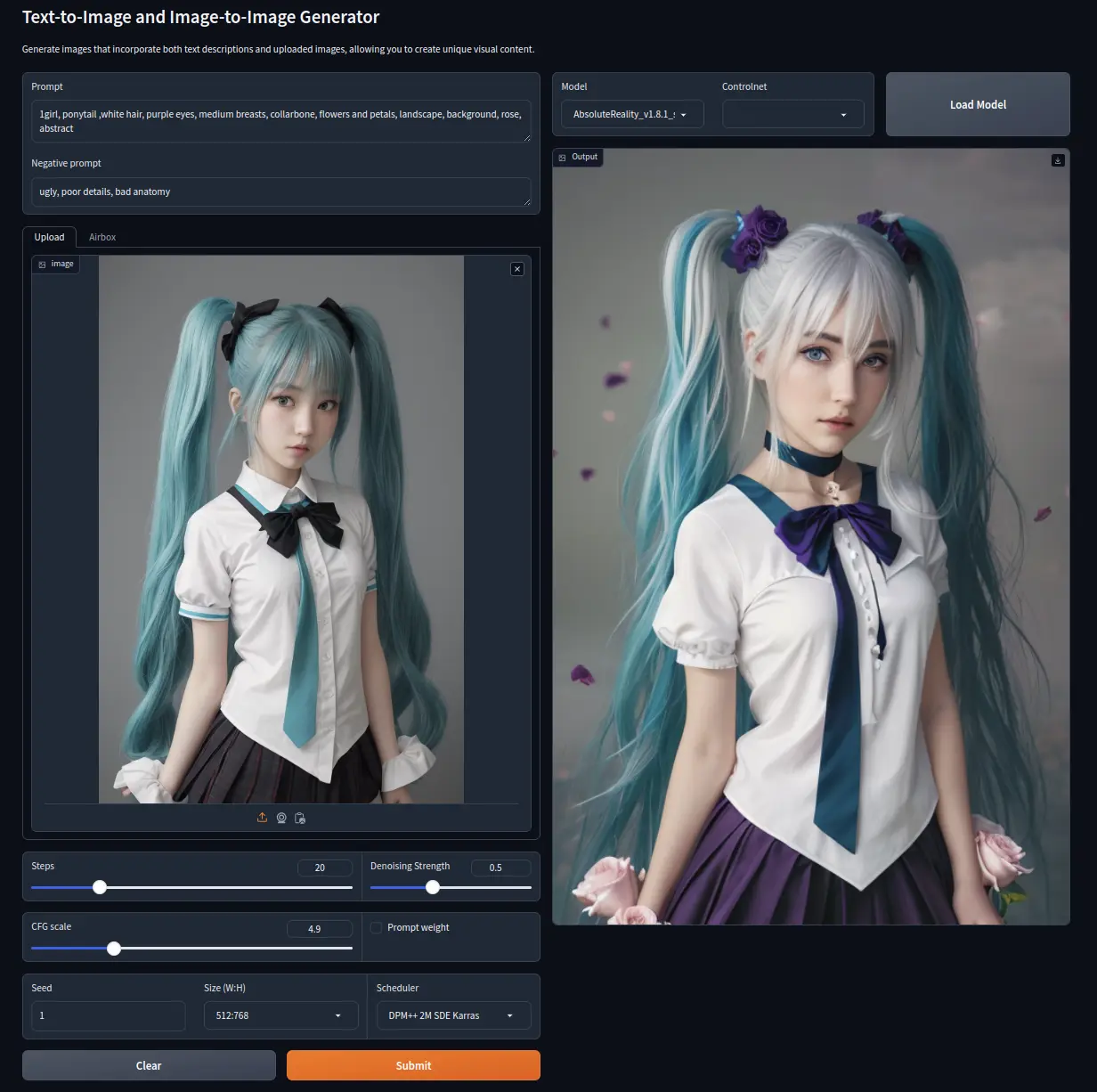
Image-to-Image
Prompt
1girl, ponytail ,white hair, purple eyes, medium breasts, collarbone,
flowers and petals, landscape, background, rose, abstract
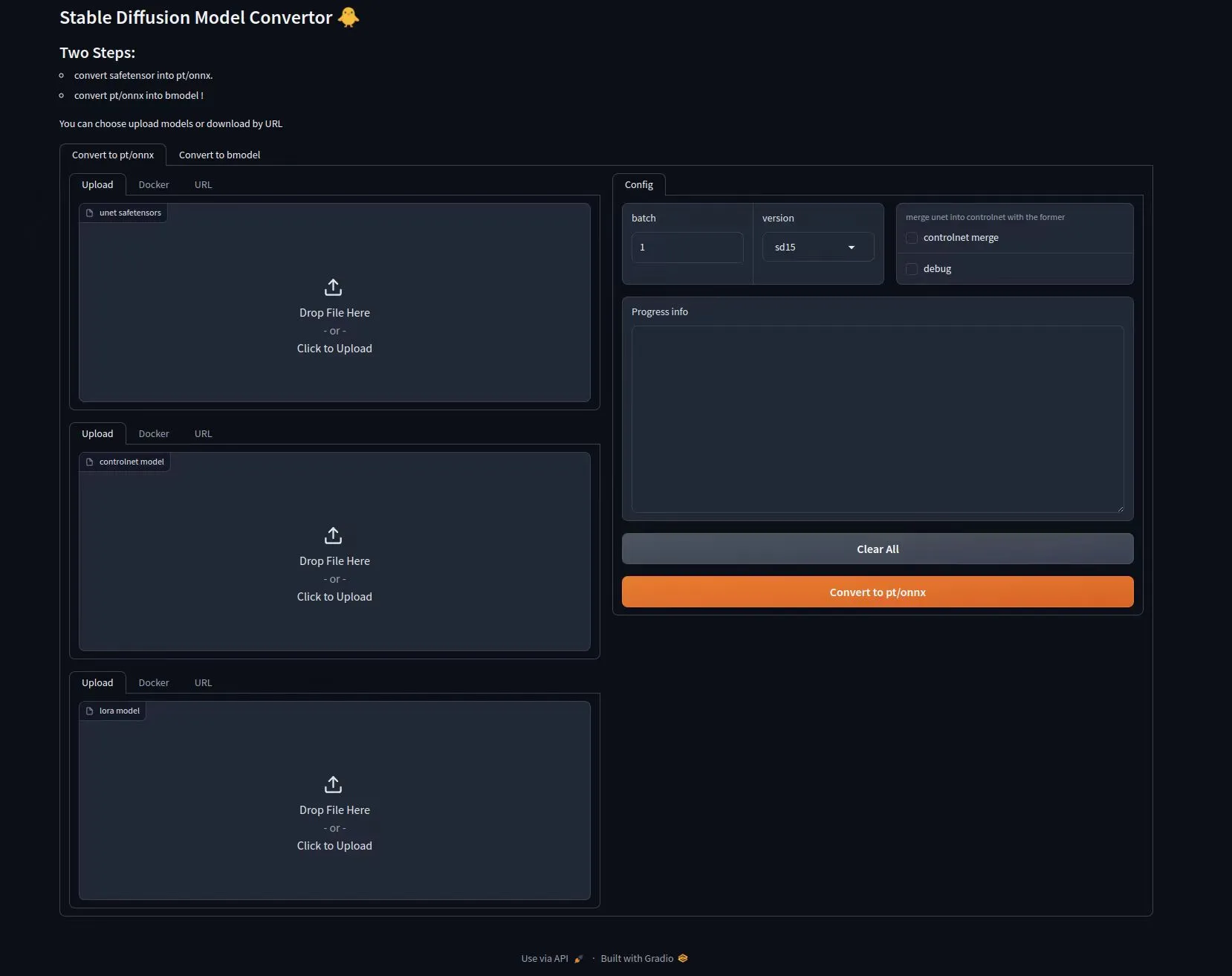
模型转换
用户可以参考这部分内容自行转换任何 stable diffusion 1.5 的模型,用户可以前往 civital 下载模型
目前有两种转换模式可以选择,命令行模式转换与 webUI交互模式
环境准备
-
x86工作站环境准备
请参考 TPU-MLIR 安装 配置 TPU-MLIR 环境
创建 docker 容器
docker run --privileged --name myname -p 8088:7860 -v $PWD:/workspace -it sophgo/tpuc_dev:latest -
配置环境
克隆项目仓库
git clone https://github.com/zifeng-radxa/SD-lcm-tpu.git在工作目录中从 Huggingface 下载 lcm-lora-sdv1-5 Lora 模型文件
git clone https://huggingface.co/latent-consistency/lcm-lora-sdv1-5安装依赖库
cd SD-lcm-tpu/model_export
pip3 install upgrade pip
pip3 install https://github.com/radxa-edge/TPU-Edge-AI/releases/download/v0.1.0/tpu_mlir-1.6.404-py3-none-any.whl
pip3 install -r requirements.txt
命令行模式转换
-
将模型从 safetensor 转为 pt/onnx
python3 export_from_safetensor_sd15_cli_wrapper.py -u xxxxx/model.safetensor -l xxxx/lora.safetensor -c xxxx/controlnet.safetensor -b 1 -o xxxxx/name-u: 要转换模型的 safetensors 文件路径-l:(可选)lora 文件路径-c:(可选)controlnet 文件路径如果需要使用LCM减少生成高质量图像所需扩散次数加快出图,要指定 -l 参数 lcm-lora-sdv1-5 文件夹路径,否则生成的模型大约需要 20 step才能同等质量的图像。
模型最后保存到 -o 指定的目录里面
.
├── text_encoder
│ └── text_encoder.onnx
├── unet
│ └── unet_fuse_1.pt
├── vae_decoder
│ └── vae_decoder.pt
└── vae_encoder
└── vae_encoder.pt -
将 pt/onnx 转为 bmodel
python3 convert_bmodel_cli_wrapper.py -n xxxxx/name -o xxxxx -s 512 512 768 512 512 768 -b 1 -v sd15-n第一步生成的文件夹路径-s输入尺寸, 支持多尺寸 latent-o(可选)目标文件家路径得到的 bmodel 在
-o xxxxx的目录里面.
├── sdv15_text.bmodel
├── sdv15_unet_multisize.bmodel
├── sdv15_vd_multisize.bmodel
└── sdv15_ve_multisize.bmodel将这个文件夹复制到 Airbox 上的 SD-lcm-tpu/models/basic 文件夹下即可
webUI 交互模式转换
在docker中启动模型转换器服务,然后使用浏览器访问运行此 docker 容器 Host 的 8088 端口
python3 gr_docker.py
-
步骤1:转换 safetensor 至 onnx/pt 格式模型
-
支持浏览器上传
-
支持选择容器内文件
-
支持 URL 自动下载 (参考这里获取 civital api token)
-
-
步骤2:转换 onnx/pt 格式模型至 bmodel
-
刷新页面
-
选择步骤 1 中生成的文件夹路径,onnx/pt 模型的父目录
-