RKLLM 使用与大语言模型部署
本文档将讲述如何使用 RKLLM 将 Huggingface 格式的大语言模型部署到 RK3588 上利用 NPU 进行硬件加速推理。
目前支持模型
- LLAMA models
- TinyLLAMA models
- Qwen models
- Phi models
- ChatGLM3-6B
- Gemma2
- Gemma3
- InternLM2 models
- MiniCPM models
- TeleChat models
- Qwen2-VL-2B-Instruct
- MiniCPM-V-2_6
- DeepSeek-R1-Distill
- Janus-Pro-1B
- InternVL2-1B
- Qwen2.5-VL-3B-Instruct
- Qwen3
这里以 Qwen2.5-1.5B-Instruct 为例子,使用 RKLLM 仓库中的示例脚本, 完整讲述如何从 0 开始部署大语言模型到搭载 RK3588 芯片的开发版上,并使用 NPU 进行硬件加速推理。
如没安装与配置 RKLLM 环境,请参考 RKLLM 安装
模型转换
RK358X 用户 TARGET_PLATFORM 请指定 rk3588 平台
这里以 Qwen2.5-1.5B-Instruct 为例子,用户也可以选择任意目前支持模型列表中的链接。
-
x86 PC 工作站中下载 Qwen2.5-1.5B-Instruct 权重文件, 如没安装 git-lfs,请自行安装
X86 Linux PCgit lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct -
激活 rkllm conda 环境, 可参考RKLLM conda 安装
X86 Linux PCconda activate rkllm -
生成 LLM 模型量化校准文件
提示对于 LLM 模型这里使用
rknn-llm/xamples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/export提供的转换脚本。对于 VLM 模型可使用
rknn-llm/examples/Qwen2-VL_Demo/export提供的转换脚本。对于多模态 VLM 模型请参考 RKLLM Qwen2-VL。X86 Linux PCcd examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/export
python3 generate_data_quant.py -m /path/to/Qwen2.5-1.5B-Instruct参数 必要性 描述 选项 path必要 Huggingface 模型文件夹路径。 N generate_data_quant.py 会生成模型量化时使用到的量化文件
data_quant.json。 -
更改
rknn-llm/xamples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/export/export_rkllm.py中 modelpath 模型路径Python Code11 modelpath = '/path/to/Qwen2.5-1.5B-Instruct' -
更改模型上下文最大值 max_context
如对 max_context 长度有需求,可在
rknn-llm/xamples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/export/export_rkllm.py中的 llm.build 函数接口中修改max_context参数的值,默认是 4096, 值越大,占用内存越多。不得超过 16,384,且必须是 32 的倍数(例如,32、64、96、...、16,384)。 -
运行模型转换脚本
X86 Linux PCpython3 export_rkllm.py转换成功后可得到 rkllm 模型, 此处应得到
Qwen2.5-1.5B-Instruct_W8A8_RK3588.rkllm,从模型命名中可以看出此模型是经过 W8A8 量化的适用于 RK3588 平台的 Qwen2.5-1.5B-Instruct RKLLM 模型。
编译可执行文件
-
下载交叉编译工具链 gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu
-
修改主程序
rknn-llm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/src/llm_demo.cpp代码这里需要注释掉 165 行的代码,RKLLM 在转换模型时,会自动解析 Hugging Face 模型 tokenizer_config.json 文件中的 chat_template 字段,故无需修改 chat_template。
CPP Code165 // rkllm_set_chat_template(llmHandle, "", "<|User|>", "<|Assistant|>"); -
修改
rknn-llm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/build-linux.sh编译脚本中 GCC_COMPILER_PATH 路径BASH8 GCC_COMPILER_PATH=/path/to/gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu -
运行模型转换脚本
X86 Linux PCcd rknn-llm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/
bash build-linux.sh生成的可执行文件在
install/demo_Linux_aarch64。
板端部署
本地终端模式
-
将转换成功后的
rkllm 模型与编译后生成的demo_Linux_aarch64文件夹拷贝到板端 -
导入环境变量
Radxa OSexport LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/demo_Linux_aarch64/lib -
运行 llm_demo,输入
exit退出Radxa OSexport RKLLM_LOG_LEVEL=1
## Usage: ./llm_demo model_path max_new_tokens max_context_len
./llm_demo /path/to/Qwen2.5-1.5B-Instruct_W8A8_RK3588.rkllm 2048 4096参数 必要性 描述 选项 path必要 RKLLM 模型文件夹路径。 N max_new_tokens必要 每轮最大生成 token 数 小于等于 max_context_len max_context_len必要 模型最大上下文范围 小于等于模型转换时的 max_context 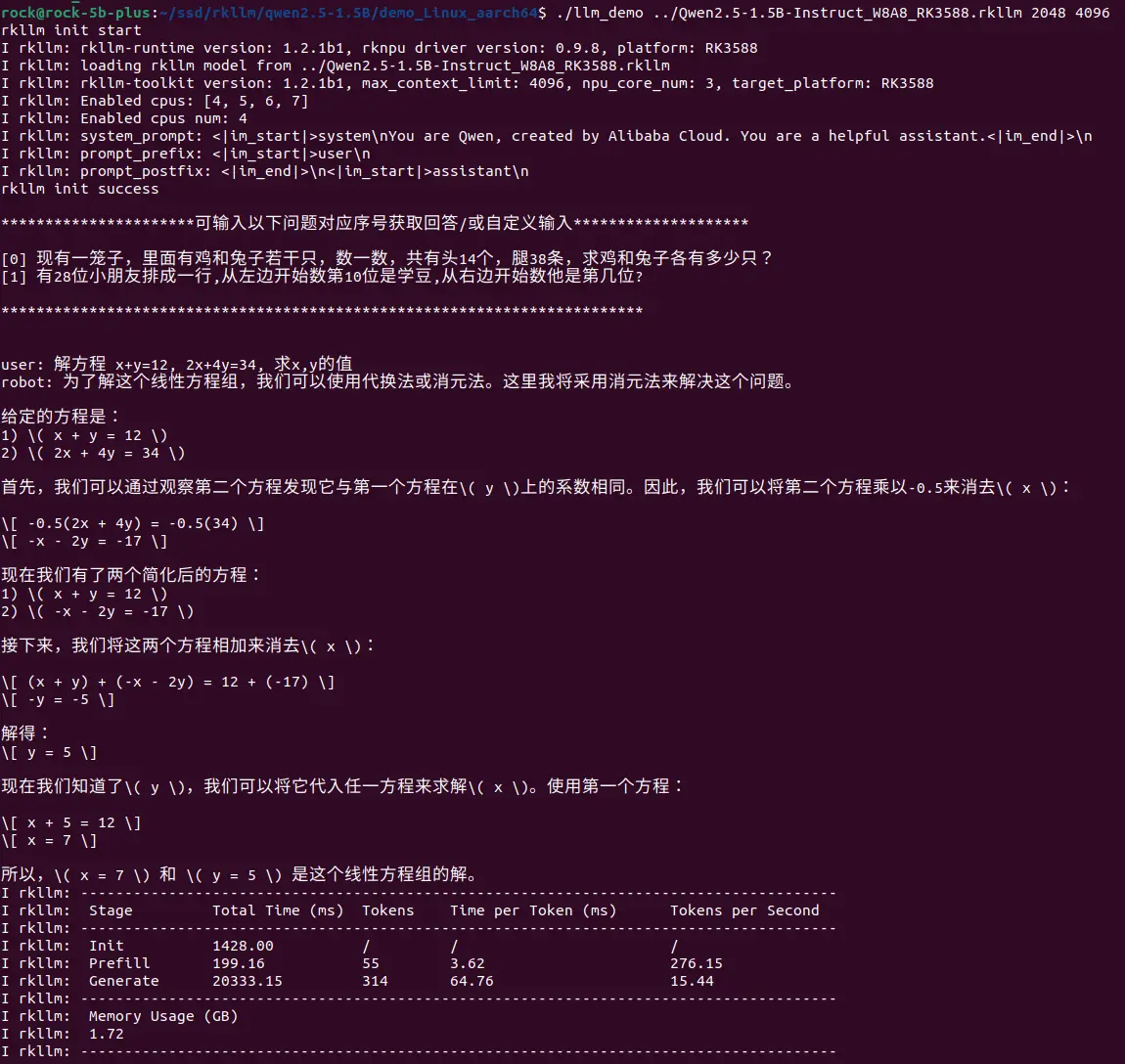
部分模型性能对比
| Model | Parameter Size | Chip | Chip Count | Inference Speed |
|---|---|---|---|---|
| TinyLlama | 1.1B | RK3588 | 1 | 15.03 token/s |
| Qwen | 1.8B | RK3588 | 1 | 14.18 token/s |
| Phi3 | 3.8B | RK3588 | 1 | 6.46 token/s |
| ChatGLM3 | 6B | RK3588 | 1 | 3.67 token/s |
| Qwen2.5 | 1.5B | RK3588 | 1 | 15.44 token/s |