RKLLM DeepSeek-R1
DeepSeek-R1 is developed by Hangzhou DeepSeek, a company focused on AI research. This model fully open-sources all training techniques and model weights, with performance aligned to the closed-source OpenAI-o1. DeepSeek has distilled six smaller models from DeepSeek-R1 for the open-source community, including Qwen2.5 and Llama3.1.
This document will guide you through deploying the DeepSeek-R1 distilled model DeepSeek-R1-Distill-Qwen-1.5B using RKLLM onto the RK3588 platform for hardware-accelerated inference using NPU.

Model File Download
Radxa has already provided precompiled rkllm models and executables. Users can directly download and use them. If you want to reference the compilation process, continue with the optional section below.
-
Use git LFS to download the precompiled rkllm model from ModelScope
X86 Linux PCgit lfs install
git clone https://www.modelscope.cn/radxa/DeepSeek-R1-Distill-Qwen-1.5B_RKLLM.git
(Optional) Model Compilation
Please complete the RKLLM setup on both PC and development board according to RKLLM Installation
For RK358X users, please specify the rk3588 platform as TARGET_PLATFORM
-
On your x86 PC workstation, download the DeepSeek-R1-Distill-Qwen-1.5B model weights. If you haven't installed git-lfs, please install it first.
X86 Linux PCgit lfs install
git clone https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B -
Activate the rkllm conda environment. You can refer to RKLLM conda Installation
X86 Linux PCconda activate rkllm -
Generate the quantization calibration file for the LLM model
X86 Linux PCcd examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/export
python3 generate_data_quant.py -m /path/to/DeepSeek-R1-Distill-Qwen-1.5BParameter Required Description Options pathRequired Path to Huggingface model folder N generate_data_quant.pywill generate a quantization file nameddata_quant.json. -
Modify the model path in
rknn-llm/xamples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/export/export_rkllm.pyPython Code11 modelpath = '/path/to/DeepSeek-R1-Distill-Qwen-1.5B_Demo' -
Adjust the maximum context length (
max_context)If you have specific requirements for
max_context, modify the value of themax_contextparameter in thellm.buildfunction withinrknn-llm/xamples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/export/export_rkllm.py. The default is 4096. A higher value increases memory usage. Do not exceed 16,384, and ensure the value is a multiple of 32 (e.g., 32, 64, 96, ..., 16,384). -
Run the model conversion script
X86 Linux PCpython3 export_rkllm.pyAfter successful conversion, you will obtain the rkllm model file
./DeepSeek-R1-Distill-Qwen-1.5B_W8A8_RK3588.rkllm. From the naming convention, this model is W8A8 quantized and designed for the RK3588 platform.
(Optional) Build Executable
-
Download the cross-compilation toolchain gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu
-
Modify the main program code in
rknn-llm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/src/llm_demo.cppComment out line 165. When converting the model, RKLLM automatically parses the
chat_templatefield in the tokenizer_config.json file of the Hugging Face model, so no manual changes are required.CPP Code165 // rkllm_set_chat_template(llmHandle, "", "<|User|>", "<|Assistant|>"); -
Update the
GCC_COMPILER_PATHin the build scriptrknn-llm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/build-linux.shBASH8 GCC_COMPILER_PATH=/path/to/gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu -
Run the build script
X86 Linux PCcd rknn-llm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/
bash build-linux.shThe generated executable will be located at
install/demo_Linux_aarch64.
Board-side Deployment
Terminal Mode
-
Copy the converted
DeepSeek-R1-Distill-Qwen-1.5B_W8A8_RK3588.rkllmmodel and the compileddemo_Linux_aarch64folder to the development board. -
Set the environment variable
Radxa OSexport LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/demo_Linux_aarch64/libtipUsers who downloaded from ModelScope can directly export the
librkllmrt.sofrom the downloaded repository. -
Run the
llm_demo. Typeexitto quit.Radxa OSexport RKLLM_LOG_LEVEL=1
## Usage: ./llm_demo model_path max_new_tokens max_context_len
./llm_demo /path/to/DeepSeek-R1-Distill-Qwen-1.5B_W8A8_RK3588.rkllm 2048 4096Parameter Required Description Options pathRequired Path to RKLLM model folder N max_new_tokensRequired Max number of tokens to generate Must be ≤ max_context_len max_context_lenRequired Maximum context size for the model Must be ≤ model's max_context 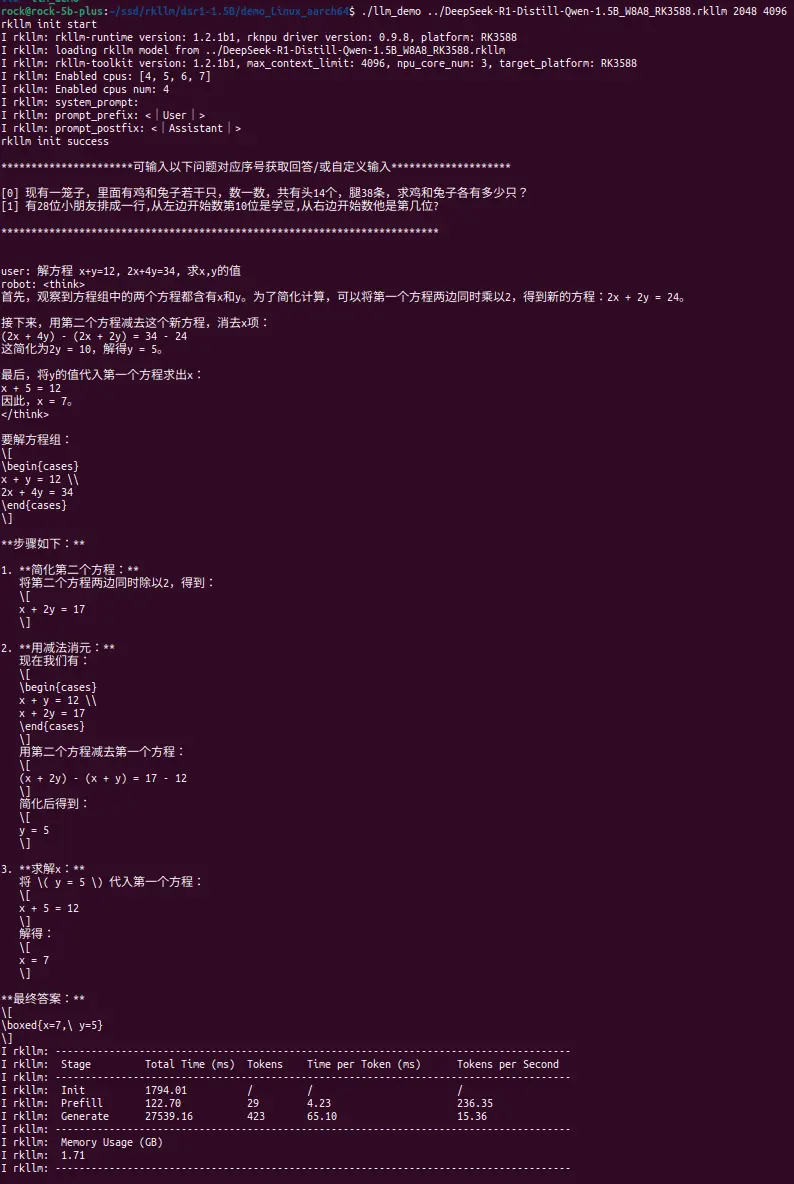
Performance Analysis
For the math problem: "Solve the equations x + y = 12, 2x + 4y = 34, find the values of x and y",
Performance on RK3588 reaches 15.36 tokens/s:
| Stage | Total Time (ms) | Tokens | Time per Token (ms) | Tokens per Second |
|---|---|---|---|---|
| Prefill | 122.70 | 29 | 4.23 | 236.35 |
| Generate | 27539.16 | 423 | 65.10 | 15.36 |
On RK3582, the performance reaches 10.61 tokens/s:
| Stage | Total Time (ms) | Tokens | Time per Token (ms) | Tokens per Second |
|---|---|---|---|---|
| Prefill | 599.71 | 81 | 7.4 | 135.07 |
| Generate | 76866.41 | 851 | 94.25 | 10.61 |