RKLLM Usage and Deploy LLM
This document describes how to deploy Huggingface-format large language models onto RK3588 using RKLLM for hardware-accelerated inference on the NPU.
Currently Supported Models
- LLAMA models
- TinyLLAMA models
- Qwen models
- Phi models
- ChatGLM3-6B
- Gemma2
- Gemma3
- InternLM2 models
- MiniCPM models
- TeleChat models
- Qwen2-VL-2B-Instruct
- MiniCPM-V-2_6
- DeepSeek-R1-Distill
- Janus-Pro-1B
- InternVL2-1B
- Qwen2.5-VL-3B-Instruct
- Qwen3
We will use Qwen2.5-1.5B-Instruct as an example and follow the sample scripts provided in the RKLLM repository to fully demonstrate how to deploy a large language model from scratch onto a development board equipped with the RK3588 chip, utilizing the NPU for hardware-accelerated inference.
If you have not installed or configured the RKLLM environment yet, please refer to RKLLM Installation.
Model Conversion
For RK358X users, please specify rk3588 as the TARGET_PLATFORM.
We will use Qwen2.5-1.5B-Instruct as an example, but you may choose any model from the list of currently supported models.
-
Download the weights of Qwen2.5-1.5B-Instruct on your x86 PC workstation. If you haven't installed git-lfs, please install it first.
X86 Linux PCgit lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct -
Activate the rkllm conda environment. You can refer to RKLLM Conda Installation.
X86 Linux PCconda activate rkllm -
Generate the LLM model quantization calibration file.
tipFor LLM models, we use the conversion script provided in
rknn-llm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/export.For VLM models, use the conversion script in
rknn-llm/examples/Qwen2-VL_Demo/export. For multimodal VLM models, please refer to RKLLM Qwen2-VL.X86 Linux PCcd examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/export
python3 generate_data_quant.py -m /path/to/Qwen2.5-1.5B-InstructParameter Required Description Options pathRequired Path to the Huggingface model folder. N The
generate_data_quant.pyscript generates the quantization filedata_quant.jsonused during model quantization. -
Update the
modelpathvariable inrknn-llm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/export/export_rkllm.pyto point to your model path.Python Code11 modelpath = '/path/to/Qwen2.5-1.5B-Instruct' -
Adjust the maximum context length
max_contextIf you need a specific
max_contextlength, modify the value of themax_contextparameter in thellm.buildfunction withinrknn-llm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/export/export_rkllm.py. The default is 4096; larger values consume more memory. It must not exceed 16,384 and must be a multiple of 32 (e.g., 32, 64, 96, ..., 16,384). -
Run the model conversion script.
X86 Linux PCpython3 export_rkllm.pyAfter successful conversion, you will get an
.rkllmmodel file — in this case,Qwen2.5-1.5B-Instruct_W8A8_RK3588.rkllm. From the filename, you can see that this model has been quantized using W8A8 and is compatible with the RK3588 platform.
Compiling the Executable
-
Download the cross-compilation toolchain gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu
-
Modify the main program code in
rknn-llm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/src/llm_demo.cppYou need to comment out line 165, since RKLLM automatically parses the
chat_templatefield from the tokenizer_config.json file when converting the model, so there's no need to manually set it.CPP Code165 // rkllm_set_chat_template(llmHandle, "", "<|User|>", "<|Assistant|>"); -
Update the
GCC_COMPILER_PATHin the build scriptrknn-llm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/build-linux.shBASH8 GCC_COMPILER_PATH=/path/to/gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu -
Run the model conversion script.
X86 Linux PCcd rknn-llm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/
bash build-linux.shThe compiled executable will be located in
install/demo_Linux_aarch64.
Deployment on Device
Local Terminal Mode
-
Copy the converted
.rkllmmodel and the compileddemo_Linux_aarch64folder to the device. -
Set up environment variables
Radxa OSexport LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/demo_Linux_aarch64/lib -
Run
llm_demo, typeexitto quitRadxa OSexport RKLLM_LOG_LEVEL=1
## Usage: ./llm_demo model_path max_new_tokens max_context_len
./llm_demo /path/to/Qwen2.5-1.5B-Instruct_W8A8_RK3588.rkllm 2048 4096Parameter Required Description Options pathRequired Path to the RKLLM model folder. N max_new_tokensRequired Maximum number of tokens to generate per round. Must be less than or equal to max_context_lenmax_context_lenRequired Maximum context size for the model. Must be less than or equal to the max_contextused during model conversion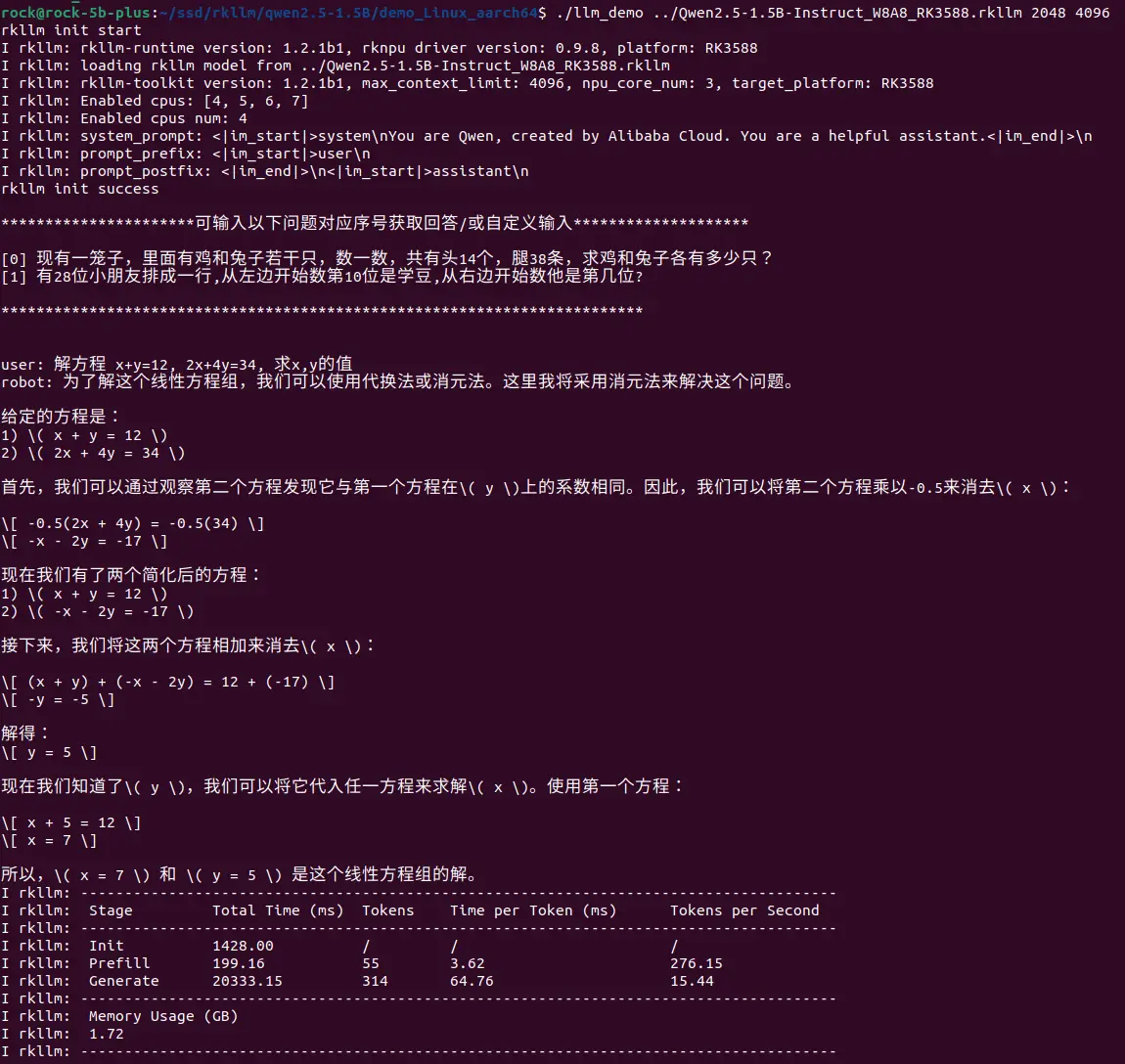
Performance Comparison for Selected Models
| Model | Parameter Size | Chip | Chip Count | Inference Speed |
|---|---|---|---|---|
| TinyLlama | 1.1B | RK3588 | 1 | 15.03 token/s |
| Qwen | 1.8B | RK3588 | 1 | 14.18 token/s |
| Phi3 | 3.8B | RK3588 | 1 | 6.46 token/s |
| ChatGLM3 | 6B | RK3588 | 1 | 3.67 token/s |
| Qwen2.5 | 1.5B | RK3588 | 1 | 15.44 token/s |