Llama3 Chatbot-TPU
Llama3 ChatBot-TPU uses the Sophon SDK to port Meta's open-source Llama3 model to the SG2300X series chips. This enables hardware-accelerated inference using local TPU and designs it into a chatbot with Gradio, allowing users to ask practical questions.
Llama3 Deployment
-
Clone the repository
git clone https://github.com/zifeng-radxa/LLM-TPU.git -
Open the Llama3 project directory
cd LLM-TPU/models/Llama3/python_demo -
This example provides the Llama-3-8B-Instruct 4-bit quantized model
llama3-8b_int4_1dev_512.bmodeland C++ precompiled files for download.Users can refer to Llama3 Model Conversion to convert Llama3 models to different quantization methods.
Users can refer to Llama3 Cpython File Compilation to compile the cpython interface binding files themselves.
# llama3-8b_int4_1dev_512.bmodel
wget https://github.com/radxa-edge/TPU-Edge-AI/releases/download/llama3/tar_downloader.sh
bash tar_downloader.sh
tar -xvf llama3-8b_int4_1dev_512.tar.gz -
Configure the environment
A virtual environment must be created to avoid affecting the normal operation of other applications. For virtual environment usage, please refer here.
python3 -m virtualenv .venv
source .venv/bin/activate -
Install dependencies
pip3 install --upgrade pip
pip3 install -r requirements.txt -
Import environment variables
Use the
lddcommand to check if thechat.cpython-38-aarch64-linux-gnu.sois linked to thelibbmlib.soatLLM-TPU/support/lib_soc/libbmlib.so.If the
libbmlib.solink path is incorrect, run the following command:export LD_LIBRARY_PATH=LLM-TPU/support/lib_soc:$LD_LIBRARY_PATH -
Start Llama3
(Optional) To modify Llama3's output language or role-playing character, please refer to Modify Llama3 Background Information.
Terminal Mode
python3 pipeline.py -m ./llama3-8b_int4_1dev_512.bmodel -t ../tokem_config-m: Specify the model path-t: Specify the token_config folder path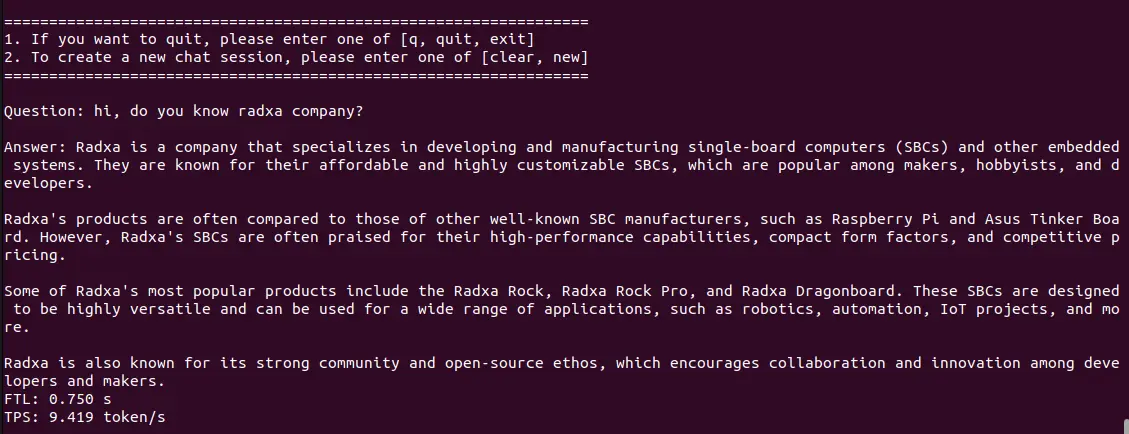
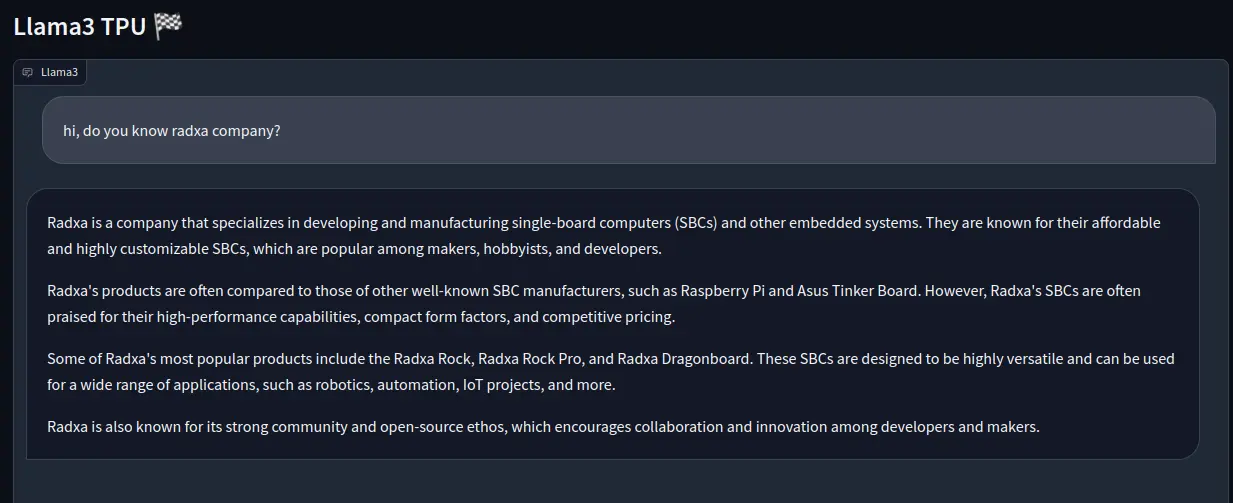
Gradio Mode
python3 web_demo.py -m ./llama3-8b_int4_1dev_512.bmodel -t ../tokem_config-m: Specify the model path-t: Specify the token_config folder pathAccess the Airbox IP address at port 8003 in your browser.
Llama3 Model Conversion
Users can refer to this document to convert Llama3 models of different quantization types to bmodel.
-
Prepare the environment on an X86 workstation
Please refer to TPU-MLIR Installation to configure the TPU-MLIR environment. Clone the repository
git clone https://github.com/zifeng-radxa/LLM-TPU.git -
Download the open-source Llama3 model by filling out the application form on Huggingface.
-
Create a virtual environment in the
LLM-TPU/models/Llama3directory.For virtual environment usage, please refer here.
python3 -m virtualenv .venv
source .venv/bin/activate
pip3 install --upgrade pip
pip3 install -r requirements.txt -
Align the model environment
Copy
LLM-TPU/models/Llama3/compile/files/Meta-Llama-3-8B-Instruct/modeling_llama.pyto the transformers library, noting that the transformers library should be in the .venv.cp ./compile/files/Meta-Llama-3-8B-Instruct/modeling_llama.py .venv/lib/python3.10/site-packages/transformers/models/llama/modeling_llama.pyReplace the
./compile/files/Meta-Llama-3-8B-Instruct/config.jsonwith the same file in the downloaded Llama-3-8B-Instruct path. -
Generate the onnx file
cd compile
python export_onnx.py --model_path your_model_path --seq_length 512--model_path: Path to the downloaded meta llama3 folder--seq_length: Fixed sequence length to export, selectable as 512, 1024, 2048, etc., as needed -
Generate the bmodel file
Exit the virtual environment before generating the bmodel
deactivateCompile the model
./compile.sh --mode int4 --name llama3-8b --seq_length 512 # same as int8--mode: Quantization mode, options are int4, int8--seq_length: Sequence length, should match the seq_length specified when generating the onnx file--name: Model name, must be llama3-8bGenerating the bmodel takes about 2 hours or more. It is recommended to have 64G memory and over 200G of disk space, otherwise OOM or no space left errors are likely.
Llama3 Cpython File Compilation
Compile executable files in the Airbox. Precompiled files are included in the llama3-8b_int4_1dev_512.tar.gz download package. If already downloaded, no need to compile.
cd python_demo
mkdir build
cd build
cmake ..
make
cp *chat* ..
Modify Llama3 Background Information
Users can modify Llama3's initialization background information to change Llama3 into different roles or output in different languages. By default, it is set as an English AI assistant: You are Llama3, a helpful AI assistant.
Users can modify the system_prompt in LLM-TPU/models/Llama3/python_demo/pipeline.py to initialize Llama3.
For example, to change Llama3 to respond in French, it can be set as:
self.system_prompt = 'Vous êtes Llama3, un assistant IA français, et vos réponses doivent être en français'
To change Llama3 into an interesting role-playing character:
self.system_prompt = 'Vous êtes Llama3, un chatbot pirate qui répond toujours en français Piratespeak'